今天这篇文章主要是对生产环境中(Java7)常用的两种垃圾收集器(ParNew:年轻代,CMS:老年代)从日志信息上进行分析,做一下总结,这样当我们在排查相应的问题时,看到 GC 的日志信息,不会再那么陌生,能清楚地知道这些日志是什么意思,GC 线程当前处在哪个阶段,正在做什么事情等。
我们的应用程序一般是运行在tomcat中,通过在tomcat中配置对应的参数可以可以生产gc日志信息:
- -verbose.gc开关可显示GC的操作内容。打开它,可以显示最忙和最空闲收集行为发生的时间、收集前后的内存大小、收集需要的时间等。
- 打开-xx:+printGCdetails开关,可以详细了解GC中的变化。
- 打开-XX:+PrintGCTimeStamps开关,可以了解这些垃圾收集发生的时间,自JVM启动以后以秒计量。
- 最后,通过-xx:+PrintHeapAtGC开关了解堆的更详细的信息。
- 为了了解新域的情况,可以通过-XX:+PrintTenuringDistribution开关了解获得使用期的对象权。
- -Xloggc:$CATALINA_BASE/logs/gc.log gc日志产生的路径
- -XX:+PrintGCApplicationStoppedTime 输出GC造成应用暂停的时间
- -XX:+PrintGCDateStamps GC发生的时间信息
还可以通过笨神的JVM平台来根据需求生成和解析JVM参数http://xxfox.perfma.com/jvm/generate
GC日志格式
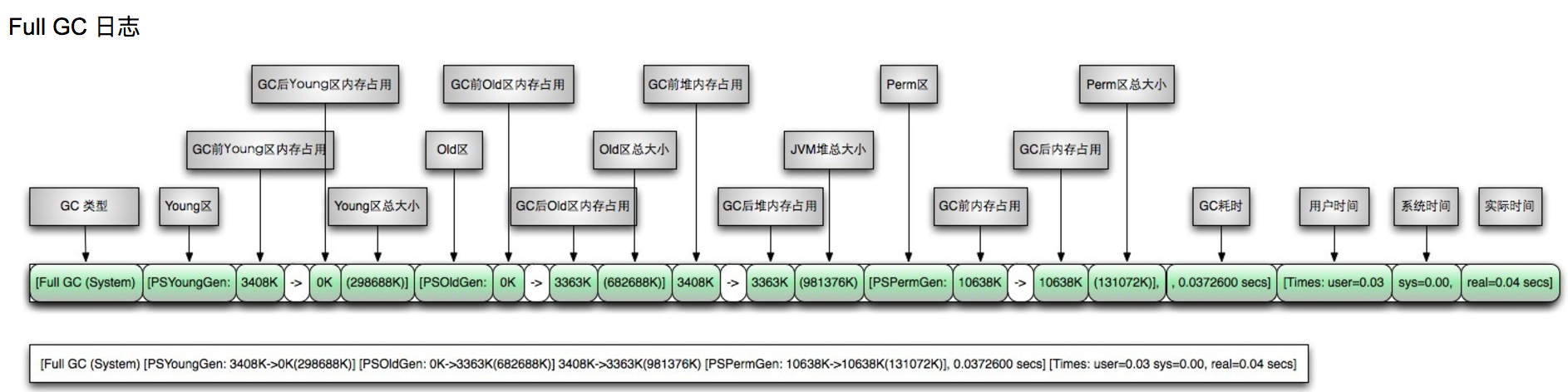
ParNew收集器日志分析
ParNew 收集器是年轻代常用的垃圾收集器,它采用的是复制算法,youngGC 时一个典型的日志信息如下所示:
1 | 2018-04-12T13:48:26.134+0800: 15578.050: [GC2018-04-12T13:48:26.135+0800: 15578.050: [ParNew: 3412467K->59681K(3774912K), 0.0971990 secs] 9702786K->6354533K(24746432K), 0.0974940 secs][Times: user=0.95 sys=0.00, real=0.09 secs] |
GC日志开头的”[GC”和“[Full GC”说明了这次垃圾收集的停顿类型。”[DefNew”、”[Tenured”、“[Perm”表示GC发生的区域,和GC收集器密切相关。比如使用Serial收集器中的新生代名为”Default New Generation”,所以显示为“[DefNew”.如果是ParNew收集器,新生代名称会变为”[ParaNew”,意思是Parallel New Generation.如果采用Parallel Scavenge收集器,那它配套的新生代名称为“[PSYoungGen”,老年代和永久代同理。
依次分析一下上面日志信息的含义:
- 2018-04-12T13:48:26.134+0800: Mirror GC 发生的时间
- 15578.050:GC 开始时,相对 JVM 启动的相对时间,单位时秒,这里是4h+;
- ParNew:收集器名称,这里是 ParNew 收集器,它使用的是并行的 mark-copy 算法,GC 过程也会 Stop the World;
- 3412467K->59681K:收集前后年轻代的使用情况,这里是 3.25G->58.28M;
- 3774912K:整个年轻代的容量,这里是 3.6G;
- 0.0971990 secs:Duration for the collection w/o final cleanup.
- 9702786K->6354533K:收集前后整个堆的使用情况,这里是 9.25G->6.06G;
- 24746432K:整个堆的容量,这里是 23.6G;
- 0.0974940 secs:ParNew 收集器标记和复制年轻代活着的对象所花费的时间(包括和老年代通信的开销、对象晋升到老年代开销、垃圾收集周期结束一些最后的清理对象等的花销);
更全一点的参数说明:
1 | [GC [<collector>: <starting occupancy1> -> <ending occupancy1>, <pause time1> secs] <starting occupancy3> -> <ending occupancy3>, <pause time3> secs] |
对于 [Times: user=0.95 sys=0.00, real=0.09 secs],这里面涉及到三种时间类型,含义如下:
- user:GC 线程在垃圾收集期间所使用的 CPU 总时间;
- sys:系统调用或者等待系统事件花费的时间;
- real:应用被暂停的时钟时间,由于 GC 线程是多线程的,导致了 real 小于 (user+real),如果是 gc 线程是单线程的话,real 是接近于 (user+real) 时间。
CMS收集器日志分析
CMS 收集器是老年代经常使用的收集器,它采用的是标记-清楚算法,应用程序在发生一次 Full GC 时,典型的 GC 日志信息如下:
1 | 2018-04-12T13:48:26.233+0800: 15578.148: [GC [1 CMS-initial-mark: 6294851K(20971520K)] 6354687K(24746432K), 0.0466580 secs] [Times: user=0.04 sys=0.00, real=0.04 secs] |
CMS Full GC 拆分开来,涉及的阶段比较多,下面分别来介绍各个阶段的情况。
阶段1:Initial Mark
这个是 CMS 两次 stop-the-wolrd 事件的其中一次,这个阶段的目标是:标记那些直接被 GC root 引用或者被年轻代存活对象所引用的所有对象,标记后示例如下所示(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC):
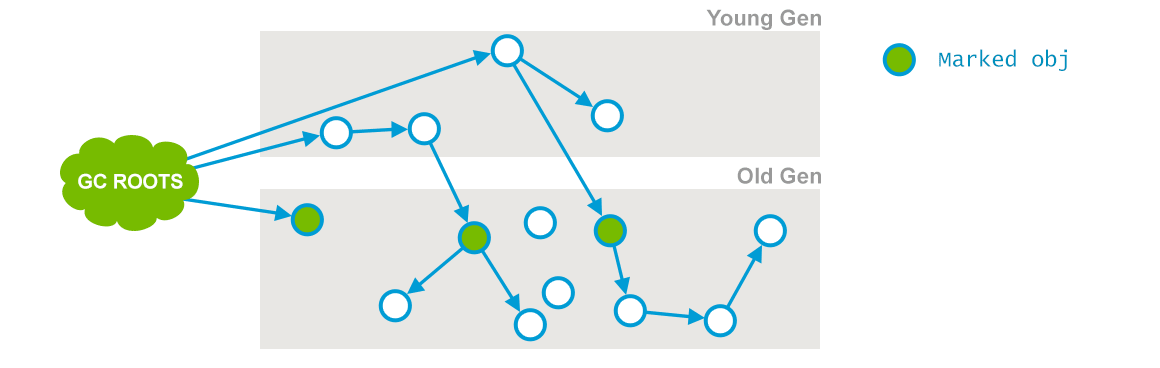
上述例子对应的日志信息为:
1 | 2018-04-12T13:48:26.233+0800: 15578.148: [GC [1 CMS-initial-mark: 6294851K(20971520K)] 6354687K(24746432K), 0.0466580 secs] [Times: user=0.04 sys=0.00, real=0.04 secs] |
逐行介绍上面日志的含义:
- 2018-04-12T13:48:26.233+0800: 15578.148:GC 开始的时间,以及相对于 JVM 启动的相对时间(单位是秒,这里大概是4.33h),与前面 ParNew 类似,下面的分析中就直接跳过这个了;
- CMS-initial-mark:初始标记阶段,它会收集所有 GC Roots 以及其直接引用的对象;
- 6294851K:当前老年代使用的容量,这里是 6G;
- (20971520K):老年代可用的最大容量,这里是 20G;
- 6354687K:整个堆目前使用的容量,这里是 6.06G;
- (24746432K):堆可用的容量,这里是 23.6G;
- 0.0466580 secs:这个阶段的持续时间;
- [Times: user=0.04 sys=0.00, real=0.04 secs]:与前面的类似,这里是相应 user、system and real 的时间统计。
阶段2
并发标记在这个阶段 Garbage Collector 会遍历老年代,然后标记所有存活的对象,它会根据上个阶段找到的 GC Roots 遍历查找。并发标记阶段,它会与用户的应用程序并发运行。并不是老年代所有的存活对象都会被标记,因为在标记期间用户的程序可能会改变一些引用,如下图所示(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC):
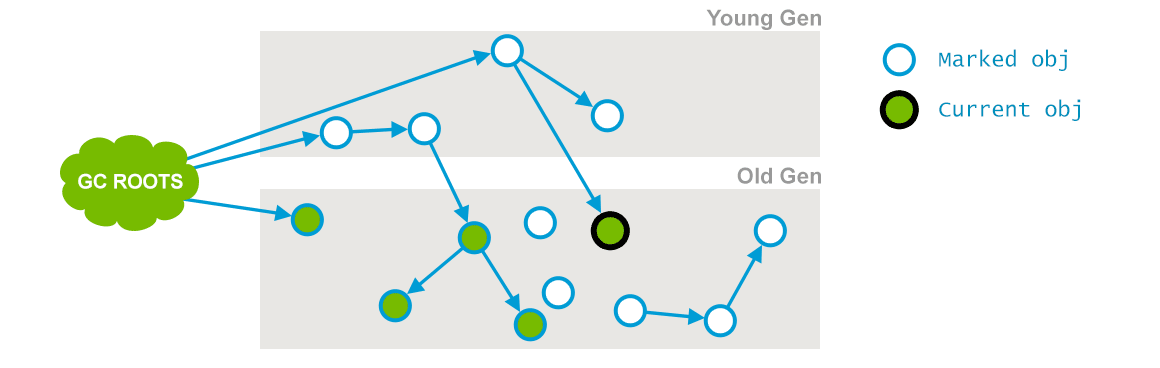
在上面的图中,与阶段1的图进行对比,就会发现有一个对象的引用已经发生了变化,这个阶段相应的日志信息如下:
1 | 2018-04-12T13:48:26.280+0800: 15578.195: [CMS-concurrent-mark-start] |
这里详细对上面的日志解释,如下所示:
- CMS-concurrent-mark:并发收集阶段,这个阶段会遍历老年代,并标记所有存活的对象;
- 0.138/0.138 secs:这个阶段的持续时间与时钟时间;
- [Times: user=1.01 sys=0.21, real=0.14 secs]:如前面所示,但是这部的时间,其实意义不大,因为它是从并发标记的开始时间开始计算,这期间因为是并发进行,不仅仅包含 GC 线程的工作。
阶段3:Concurrent Preclean
Concurrent Preclean:这也是一个并发阶段,与应用的线程并发运行,并不会 stop 应用的线程。在并发运行的过程中,一些对象的引用可能会发生变化,但是这种情况发生时,JVM 会将包含这个对象的区域(Card)标记为 Dirty,这也就是 Card Marking。如下图所示(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC:
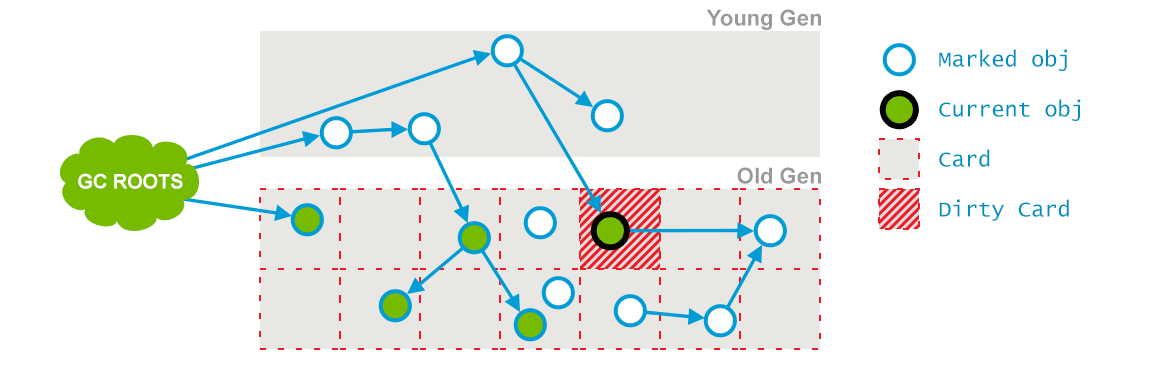
在pre-clean阶段,那些能够从 Dirty 对象到达的对象也会被标记,这个标记做完之后,dirty card 标记就会被清除了,如下(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC)
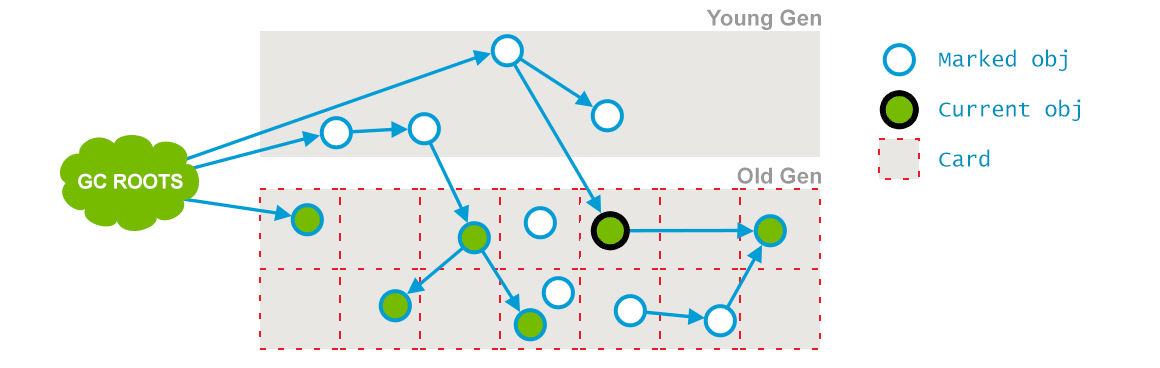
这个阶段相应的日志信息如下:
1 | 2018-04-12T13:48:26.418+0800: 15578.334: [CMS-concurrent-preclean-start] |
其含义为:
- CMS-concurrent-preclean:Concurrent Preclean 阶段,对在前面并发标记阶段中引用发生变化的对象进行标记;
- 0.056/0.057 secs:这个阶段的持续时间与时钟时间;
- [Times: user=0.20 sys=0.12, real=0.06 secs]:同并发标记阶段中的含义。
阶段4:Concurrent Abortable Preclean
这也是一个并发阶段,但是同样不会影响影响用户的应用线程,这个阶段是为了尽量承担 STW(stop-the-world)中最终标记阶段的工作。这个阶段持续时间依赖于很多的因素,由于这个阶段是在重复做很多相同的工作,直接满足一些条件(比如:重复迭代的次数、完成的工作量或者时钟时间等)。这个阶段的日志信息如下:
1 | 2018-04-12T13:48:26.476+0800: 15578.391: [CMS-concurrent-abortable-preclean-start] |
- CMS-concurrent-abortable-preclean:Concurrent Abortable Preclean 阶段;
- 3.506/3.514 secs:这个阶段的持续时间与时钟时间,本质上,这里的 gc 线程会在 STW 之前做更多的工作,通常会持续 5s 左右;
- [Times: user=11.93 sys=6.77, real=3.51 secs]:同前面。
阶段5:Final Remark
这是第二个STW阶段,也是CMS中的最后一个,这个阶段的目标是标记所有老年代所有的存活对象,由于之前的阶段是并发执行的,gc 线程可能跟不上应用程序的变化,为了完成标记老年代所有存活对象的目标,STW 就非常有必要了。通常 CMS 的 Final Remark 阶段会在年轻代尽可能干净的时候运行,目的是为了减少连续 STW 发生的可能性(年轻代存活对象过多的话,也会导致老年代涉及的存活对象会很多)。这个阶段会比前面的几个阶段更复杂一些,相关日志如下:
1 | 2018-04-12T13:48:29.991+0800: 15581.906: [GC[YG occupancy: 1805641 K (3774912 K)]2018-04-12T13:48:29.991+0800: 15581.906: [GC2018-04-12T13:48:29.991+0800: 15581.906: |
对上面的日志进行分析:
- YG occupancy: 1805641 K (3774912 K):年轻代当前占用量及容量,这里分别是 1.71G 和 3.6G;
- ParNew:…:触发了一次 young GC,这里触发的原因是为了减少年轻代的存活对象,尽量使年轻代更干净一些;
- [Rescan (parallel) , 0.0429390 secs]:这个 Rescan 是当应用暂停的情况下完成对所有存活对象的标记,这个阶段是并行处理的,这里花费了 0.0429390s;
- [weak refs processing, 0.0027800 secs]:第一个子阶段,它的工作是处理弱引用;
- [class unloading, 0.0033120 secs]:第二个子阶段,它的工作是:unloading the unused classes;
- [scrub symbol table, 0.0016780 secs] … [scrub string table, 0.0004780 secs]:最后一个子阶段,它的目的是:cleaning up symbol and string tables which hold class-level metadata and internalized string respectively,时钟的暂停也包含在这里;
- 6299829K(20971520K):这个阶段之后,老年代的使用量与总量,这里分别是 6G 和 20G;
- 6348225K(24746432K):这个阶段之后,堆的使用量与总量(包括年轻代,年轻代在前面发生过 GC),这里分别是 6.05G 和 23.6G;
- 0.1365130 secs:这个阶段的持续时间;
- [Times: user=1.24 sys=0.00, real=0.14 secs]:对应的时间信息。
经历过这五个阶段之后,老年代所有存活的对象都被标记过了,现在可以通过清除算法去清理那些老年代不再使用的对象。
阶段6:Concurrent Sweep
这里不需要 STW,它是与用户的应用程序并发运行,这个阶段是:清除那些不再使用的对象,回收它们的占用空间为将来使用。如下图所示(插图来自:GC Algorithms:Implementations —— Concurrent Mark and Sweep —— Full GC)
这个阶段对应的日志信息如下(这中间又发生了一次 Young GC):
1 | 2018-04-12T13:48:30.128+0800: 15582.043: [CMS-concurrent-sweep-start] |
分别介绍一下:
- CMS-concurrent-sweep:这个阶段主要是清除那些没有被标记的对象,回收它们的占用空间;
- 8.193/8.284 secs:这个阶段的持续时间与时钟时间;
- [Times: user=30.34 sys=16.44, real=8.28 secs]:同前面;
阶段7:Concurrent Reset
这个阶段也是并发执行的,它会重设 CMS 内部的数据结构,为下次的 GC 做准备,对应的日志信息如下:
1 | 2018-04-12T13:48:38.419+0800: 15590.334: [CMS-concurrent-reset-start] |
日志详情分别如下:
- CMS-concurrent-reset:这个阶段的开始,目的如前面所述;
- 0.044/0.044 secs:这个阶段的持续时间与时钟时间;
- [Times: user=0.15 sys=0.10, real=0.04 secs]:同前面。
总结
CMS 通过将大量工作分散到并发处理阶段来在减少 STW 时间,在这块做得非常优秀,但是 CMS 也有一些其他的问题:
- CMS 收集器无法处理浮动垃圾( Floating Garbage),可能出现 “Concurrnet Mode Failure” 失败而导致另一次 Full GC 的产生,可能引发串行 Full GC;
- 空间碎片,导致无法分配大对象,CMS 收集器提供了一个 -XX:+UseCMSCompactAtFullCollection 开关参数(默认就是开启的),用于在 CMS 收集器顶不住要进行 Full GC 时开启内存碎片的合并整理过程,内存整理的过程是无法并发的,空间碎片问题没有了,但停顿时间不得不变长;
- 对于堆比较大的应用上,GC 的时间难以预估。
CMS 的一些缺陷也是 G1 收集器兴起的原因。关于G1收集器的日志可以查看这里https://tech.meituan.com/g1.html