上一篇 讲了Kafka Producer发送消息的主体流程,这一篇我们关注下Kafka的网络层是如何实现的。
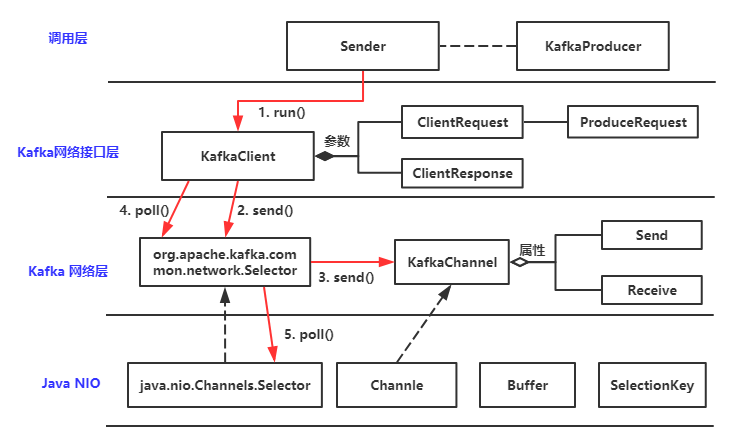
开局一张图
上面是Kafka producer网络层的主体流程,先看下有一个大体印象。
Kafka的底层使用的是Java NIO,Kafka中针对NIO的Selector的封装类也叫Selector,对Channel的封装类叫做KafkaChannel。后面如果没有特殊说明,Selector都是指Kafka中的Selector。
先来回顾下Kafka 发送消息的代码
1 2 3 4 KafkaProducer<String,String> producer = createProducer(); for (int i = 0 ; i < 10 ;i++) { producer.send(new ProducerRecord<>("codeTest" ,"key" + (i+1 ),"value" + (i+1 ))); }
上面的代码中首先会初始化KafkaProducer,在初始化KafkaProducer的时候,同时我们也会初始化Kafka发送消息的客户端
1 2 3 4 KafkaClient client = kafkaClient != null ? kafkaClient : new NetworkClient( new Selector(config.getLong(ProducerConfig.CONNECTIONS_MAX_IDLE_MS_CONFIG), this .metrics, time, "producer" , channelBuilder, logContext), ...);
创建NetworkClient(implements KafkaClient)的同时会创建一个Selector,这个是对java.nio.Selector的封装,发送请求,接收响应,处理连接完成以及现有的断开连接都是通过它的poll()方法调用完成的。
我们都知道Kafka读写消息都是通过leader的,只有知道了leader才能发送消息到kafka,在我们的大家好,我是Kafka 一文中,我们讲了首先会发起metadata request,从中就可以获取到集群元信息(leader,partiton,ISR列表等),那么是在哪里发起metadata request的呢?
调用KafkaProducer的doSend()(send()–>doSend())方法时,第一步就是通过waitOnMetadata 等待集群元数据(topic,partition,node等)可用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 Cluster cluster = metadata.fetch(); Integer partitionsCount = cluster.partitionCountForTopic(topic); if (partitionsCount != null && (partition == null || partition < partitionsCount)) return new ClusterAndWaitTime(cluster, 0 ); do { int version = metadata.requestUpdate(); sender.wakeup(); metadata.awaitUpdate(version, remainingWaitMs); cluster = metadata.fetch(); elapsed = time.milliseconds() - begin; remainingWaitMs = maxWaitMs - elapsed; partitionsCount = cluster.partitionCountForTopic(topic); } while (partitionsCount == null );
如果metadata中不包含对应topic的metadata信息,那么就请求更新metadata,如果没有更新则一直会在这个while循环中,这个循环主要做了以下几件事
调用metadata.requestUpdate();将needUpdate属性设置为true(表示强制更新),返回当前version(用于判断是否更新过了)
唤醒Sender线程,实际上是唤醒NetworkClient中Selector,避免Selector一直在poll中等待
执行metadata.awaitUpdate等待metadata的更新,未更新则一直阻塞。
1 2 3 4 5 6 7 8 9 10 11 public synchronized void awaitUpdate (final int lastVersion, final long maxWaitMs) throws InterruptedException long begin = System.currentTimeMillis(); long remainingWaitMs = maxWaitMs; while ((this .version <= lastVersion) && !isClosed()) { if (remainingWaitMs != 0 ) wait(remainingWaitMs); long elapsed = System.currentTimeMillis() - begin; remainingWaitMs = maxWaitMs - elapsed; } }
发起请求 现在我们知道了会等待元数据更新,那么到底是在哪里更新的呢?上面有讲到唤醒了Sender线程,在run()方法中会去调用KafkaClient.poll()方法,这里会对metadata request进行处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Override public List<ClientResponse> poll (long timeout, long now) long metadataTimeout = metadataUpdater.maybeUpdate(now); this .selector.poll(Utils.min(timeout, metadataTimeout, defaultRequestTimeoutMs)); ... handleCompletedReceives(responses, updatedNow); ... return responses; }
现在看看metadata request如何发送的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 private long maybeUpdate (long now, Node node) String nodeConnectionId = node.idString(); if (canSendRequest(nodeConnectionId, now)) { sendInternalMetadataRequest(metadataRequest, nodeConnectionId, now); return defaultRequestTimeoutMs; } if (connectionStates.canConnect(nodeConnectionId, now)) { initiateConnect(node, now); return reconnectBackoffMs; } return Long.MAX_VALUE; }
上面的代码先查看是否可以发送请求,如果可以发送请求就直接将数据设置到KafkaChannel中。如果不能发送就查看当前是否可以连接,如果可以则初始化连接,初始化连接的代码在Selector.connect()方法中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @Override public void connect (String id, InetSocketAddress address, int sendBufferSize, int receiveBufferSize) throws IOException SocketChannel socketChannel = SocketChannel.open(); configureSocketChannel(socketChannel, sendBufferSize, receiveBufferSize); boolean connected = doConnect(socketChannel, address); SelectionKey key = registerChannel(id, socketChannel, SelectionKey.OP_CONNECT); if (connected) { immediatelyConnectedKeys.add(key); key.interestOps(0 ); } } private SelectionKey registerChannel (String id, SocketChannel socketChannel, int interestedOps) throws IOException SelectionKey key = socketChannel.register(nioSelector, interestedOps); KafkaChannel channel = buildAndAttachKafkaChannel(socketChannel, id, key); this .channels.put(id, channel); return key; }
如果熟悉NIO的话,上面的代码看上去就很熟悉,主要就是设置设置channel以及selectionKey的关系。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public class KafkaChannel private final TransportLayer transportLayer; private final MemoryPool memoryPool; private NetworkReceive receive; private Send send; } public class Selector implements Selectable , AutoCloseable private final java.nio.channels.Selector nioSelector; private final Map<String, KafkaChannel> channels; private final List<Send> completedSends; private final List<NetworkReceive> completedReceives; private final Map<KafkaChannel, Deque<NetworkReceive>> stagedReceives; private final Set<SelectionKey> immediatelyConnectedKeys; private final MemoryPool memoryPool; }
轮询数据 初始化连接完成之后,这个时候就是开始轮询了,在Selector.poll()方法中关于数据读写的逻辑如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public void poll (long timeout) throws IOException int numReadyKeys = select(timeout); if (numReadyKeys > 0 || !immediatelyConnectedKeys.isEmpty() || dataInBuffers) { Set<SelectionKey> readyKeys = this .nioSelector.selectedKeys(); pollSelectionKeys(readyKeys, false , endSelect); readyKeys.clear(); pollSelectionKeys(immediatelyConnectedKeys, true , endSelect); immediatelyConnectedKeys.clear(); } addToCompletedReceives(); } void pollSelectionKeys (Set<SelectionKey> selectionKeys, boolean isImmediatelyConnected, long currentTimeNanos) for (SelectionKey key : determineHandlingOrder(selectionKeys)) { KafkaChannel channel = channel(key); boolean sendFailed = false ; if (channel.ready() && (key.isReadable() || channel.hasBytesBuffered()) && !hasStagedReceive(channel) && !explicitlyMutedChannels.contains(channel)) { NetworkReceive networkReceive; while ((networkReceive = channel.read()) != null ) { if (!stagedReceives.containsKey(channel)) stagedReceives.put(channel, new ArrayDeque<NetworkReceive>()); Deque<NetworkReceive> deque = stagedReceives.get(channel); deque.add(receive); } } if (channel.ready() && key.isWritable()) { Send send = channel.write(); } }
上面的代码主要做了两件事儿
读取网络返回的请求,从Channel读进Buffer,Buffer是有容量限制的,所以可能一次只能读取一个req的部分数据。只有读到一个完整的req的情况下,channel.read()方法才返回非null
发送数据,从Buffer写入Channel,这里发起了真正的网络IO
读出数据后,会先放到stagedReceives集合中,然后在addToCompletedReceives()方法中对于每个channel都会从stagedReceives取出一个NetworkReceive(如果有的话),放入到completedReceives中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 private void addToCompletedReceives () if (!this .stagedReceives.isEmpty()) { Iterator<Map.Entry<KafkaChannel, Deque<NetworkReceive>>> iter = this .stagedReceives.entrySet().iterator(); while (iter.hasNext()) { Map.Entry<KafkaChannel, Deque<NetworkReceive>> entry = iter.next(); KafkaChannel channel = entry.getKey(); if (!explicitlyMutedChannels.contains(channel)) { Deque<NetworkReceive> deque = entry.getValue(); addToCompletedReceives(channel, deque); if (deque.isEmpty()) iter.remove(); } } } }
根据官方代码注释这样做的原因有2点,还可以参考(https://github.com/apache/kafka/pull/5920)。
对于SSL连接,数据内容是加密的,不能精准的确定本次需要读取的数据大小,只能尽可能的多读,这样会导致可能会比请求的数据读的要多。那如果该channel之后没有数据可以读,会导致多读的数据将不会被处理。
kafka需要确保一个channel上request被处理的顺序是其发送的顺序。因此对于每个channel而言,每次poll上层最多只能看见一个请求,当该请求处理完成之后,再处理其他的请求。对Server端和Client端来说处理方式不一样。Selector这个类在Client和Server端都会调用,所以这里存在两种情况
应用在 Server 端时,Server 为了保证消息的时序性,在 Selector 中提供了两个方法:mute(String id) 和 unmute(String id),对该 KafkaChannel 做标记来保证同时只能处理这个 Channel 的一个 request(可以理解为排它锁)。当 Server 端接收到 request 后,先将其放入 stagedReceives 集合中,此时该 Channel 还未 mute,这个 Receive 会被放入 completedReceives 集合中。Server 在对 completedReceives 集合中的 request 进行处理时,会先对该 Channel mute,处理后的 response 发送完成后再对该 Channel unmute,然后才能处理该 Channel 其他的请求
应用在 Client 端时,Client 并不会调用 Selector 的 mute() 和 unmute() 方法,client 发送消息的时序性而是通过 InFlightRequests(保存了max.in.flight.requests.per.connection参数的值) 和 RecordAccumulator 的 mutePartition 来保证的,因此对于 Client 端而言,这里接收到的所有 Receive 都会被放入到 completedReceives 的集合中等待后续处理。
处理响应 现在响应数据已经收到了,在KafkaClient.poll方法中会调用handleCompletedReceives()方法处理已经完成的响应
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 private void handleCompletedReceives (List<ClientResponse> responses, long now) for (NetworkReceive receive : this .selector.completedReceives()) { String source = receive.source(); InFlightRequest req = inFlightRequests.completeNext(source); Struct responseStruct = parseStructMaybeUpdateThrottleTimeMetrics(receive.payload(), req.header, throttleTimeSensor, now); AbstractResponse body = AbstractResponse.parseResponse(req.header.apiKey(), responseStruct); maybeThrottle(body, req.header.apiVersion(), req.destination, now); if (req.isInternalRequest && body instanceof MetadataResponse) metadataUpdater.handleCompletedMetadataResponse(req.header, now, (MetadataResponse) body); else if (req.isInternalRequest && body instanceof ApiVersionsResponse) handleApiVersionsResponse(responses, req, now, (ApiVersionsResponse) body); else responses.add(req.completed(body, now)); } }
至此,发送metadata request的流程已经分析完毕,发送消息的流程和metadata request的流程大体是一致的,这里就不做过多分析了。
总结 总结下发送流程
sender 线程第一次调用 poll() 方法时,初始化与 node 的连接;
sender 线程第二次调用 poll() 方法时,发送 Metadata 请求;
sender 线程第三次调用 poll() 方法时,获取 metadataResponse,并更新 metadata。
经过上述 sender 线程三次调用 poll()方法,所请求的 metadata 信息才会得到更新,此时 Producer 线程也不会再阻塞,开始发送消息。
分析Kafka网络层的构成的时候,一定要搞清楚NIO的处理流程,进一步理解Kafka中的Selector和KafkaChannel。
本次源代码分析基于kafka-client-2.0.0版本。