前言
我相信大家在项目中或多或少的都使用过线程,而线程是宝贵的资源,不能频繁的创建,应当给其他任务进行复用,所以就有了我们的线程池。
线程池的使用
你知道我们如何创建线程池吗?
这我当然知道了,JDK主要提供了三种创建线程池的方法
- Executors.newFixedThreadPool(int nThreads) : 创建固定线程数量的线程池
- Executors.newSingleThreadExecutor() : 创建单个线程的线程池
- Executors.newCachedThreadPool() : 创建一个”无限大小”的线程池
线程池如何使用
1 | ExecutorService threadPool = Executors.newFixedThreadPool(5); |
线程池的原理
你给我讲讲线程池的原理呢?
线程池核心参数以及状态
上面说的创建线程池的方法实际上都是通过创建ThreadPoolExecutor这个类来实现的,所以我们直接看这个类的实现原理即可。
首先来看看它的构造方法
1 | public ThreadPoolExecutor(int corePoolSize, |
先说下它这几个核心参数的含义
- corePoolSize : 线程池核心线程数量
- maximumPoolSize : 线程池最大线程数量
- keepAliveTime : 非核心线程的超时时长,当系统中非核心线程闲置时间超过keepAliveTime之后,则会被回收。如果ThreadPoolExecutor的allowCoreThreadTimeOut属性设置为true,则该参数也表示核心线程的超时时长
- unit : 超时时长单位
- workQueue : 线程池中的任务队列,该队列主要用来存储已经被提交但是尚未执行的任务
- handler : 当线程池无法处理任务的时候的处理策略
当然只是知道这几个参数也没有什么太大的作用,我们还是要着眼全局来看ThreadPoolExecutor类。
首先来认识下线程池中定义的状态,它们一直贯穿在整个主体
1 | // ctl存储了两个值,一个是线程池的状态,另一个是活动线程数(workerCount) |
从上面的成员变量的定义我们可以知道,线程池最多允许5亿个(2^29-1)个线程活动,那么为什么不是2^31-1呢?因为设计者觉得这个值已经够大了,如果将来觉得这是一个瓶颈的话,会把这个换成Long类型。
同时线程池这里也存在了五个状态,它们解决着线程池的生命周期。
- RUNNING : 运行状态。接受新的task并且处理队列中的task
- SHUTDOWN : 关闭状态(调用了shutdown方法)。不接受新的task,但是要处理队列中的task
- STOP : 停止状态(调用了shutdownNow方法)。不接受新的task,也不处理队列中的task,并且要中断正在处理的task
- TIDYING : 所有的task都已终止了,workerCount (活动终止状态,当执行 terminated() 后会更新为这个状态线程数) 为0,线程池进入该状态后会调用 terminated() 方法进入TERMINATED 状态
- TERMINATED : 终止状态,当执行 terminated() 后会更新为这个状态
状态流转图如下: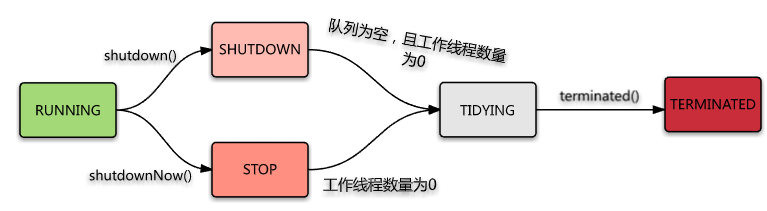
原理
我们知道当我们执行一个task的时候,调用的是execute方法
1 | public void execute(Runnable command) { |
而在addWorker方法中还存在有一些必要的判断逻辑,比如当前线程池是否是非running状态,队列是否为空等条件,当然最主要的逻辑还是判断当前工作线程数量是否大于maximumPoolSize以及启动工作线程执行任务。
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
所以,总结下线程池的工作流程 如下:
- 提交一个任务,如果线程池中的工作线程数小于corePoolSize,则新建一个工作线程执行任务
- 如果线程池当前的工作线程已经等于了corePoolSize,则将新的任务放入到工作队列中正在执行
- 如果工作队列已经满了,并且工作线程数小于maximumPoolSize,则新建一个工作线程来执行任务
- 如果当前线程池中工作线程数已经达到了maximumPoolSize,而新的任务无法放入到任务队列中,则采用对应的策略进行相应
的处理(默认是拒绝策略)
如果你觉得上面不好记,我给你讲个火锅店的故事你就更加明白了。
以前有个火锅店,叫做朱帅帅火锅,老板是个刚辞掉程序员工作出来创业的帅小伙子,火锅店不大,只能摆上10张桌子(corePoolSize),如果吃火锅的来得早就可以去店里面坐(店里有空调),来晚了,店里面坐满了,后面来的人就要排队了(workQueue)。
排队的人数越来越多,朱帅帅一看不是办法,就给外面摆了几张临时桌子(非核心工作线程),让客人在外面吃。如果店里面有人吃完了或者外面临时桌子吃完了就让排队的人去吃。后面时间晚了,没有排队的人了,老板就让人撤了外面的临时桌子,毕竟摆在外面也不太好,而且还怕城管来。如果生意特别好,又来了特别多的人,已经超出火锅店的服务能力了,就只能喊他们去别家了。
上面的故事,你要品,细细的品,最后你会发现,代码来源于生活。
上面一直说到工作线程,工作线程到底是个什么鬼?其实工作线程指的就是我们的Worker类,它是ThreadPoolExecutor中的私有类
1 | private final class Worker |
可以看到Woker不仅继承了AbstractQueuedSynchronizer(实现独占锁功能),还实现了Runnable接口。
实际上线程池中的每一个线程被封装成一个Worker对象,ThreadPool维护的其实就是一组Worker对象
Worker用自己作为task构造一个线程,同时把外层任务赋值给自己的task成员变量,相当于对task做了一个包装。
addWorker()方法中执行了worker.thread.start(),实际上执行的就是Worker的runWorker方法。
1 | final void runWorker(Worker w) { |
** 上面的代码中尤其需要注意的是getTask()中的第3点,它的目的是控制线程池有效的工作线程数量。
从之前的分析我们可以知道,如果当前线程池的工作线程数量超过了corePoolSize且小于maximumPoolSize,并且workQueue已满,则可以增加工作线程,但这时如果超时没有获取到任务,也就是timedOut为true的情况,说明workQueue已经为空了,也就说明了线程池中不需要那么多线程来执行任务了,可以把多于corePoolSize数量的线程销毁掉,保持线程数量在corePoolSize即可。**
拒绝策略
你刚才说到拒绝策略,都有哪些拒绝策略呀?
主要有下面4种拒绝策略
- AbortPolicy : 始终抛出RejectedExecutionException
- CallerRunsPolicy : 如果线程池未关闭,则交给调用线程池的线程执行
- DiscardPolicy : 直接丢弃任务,啥也不做
- DiscardOldestPolicy : 丢弃队列里最老的任务,然后将当前这个任务重新提交给线程池。
如果这四种策略都不满足需求,可以自己实现自己的拒绝策略。
通过Executors创建的线程池不同之处
你给我说说你开头说的通过Executors创建的线程池三者有何不同吗?
newFixedThreadPool
固定线程数量的线程池,corePoolSize等于maximumPoolSize,采用的阻塞队列是LinkedBlockingQueue,是一个无界队列,当任务量突然很大,线程池来不及处理,就会将任务一直添加到队列中,就有可能导致内存溢出。
newSingleThreadExecutor
创建单个线程的线程池,corePoolSize = maximumPoolSize = 1,也采用的LinkedBlockingQueue这个无界队列,当任务量很大,线程池来不及处理,就有可能会导致内存溢出。
newCachedThreadPool
创建可缓存的线程池,corePoolSize = 1,maximumPoolSize = Interger.MAX_VALUE;但是使用的是SynousQueue,这个队列比较特殊,内部没有结构来存储任何元素,所以如果任务数很大,而创建的那个线程(corePoolSize=1)迟迟没有处理完成任务,就会一直创建线程来处理,也有OOM的可能。
cacheThreadPool中的cache其实指的就是SynousQueue,当往这个队列插入数据的时候,如果没有任务来取,插入这个过程会被阻塞。
你既然说了都有可能OOM,那么应该如何创建线程池呢?
实际使用中不建议通过Executors来创建线程池,而是通过 new ThreadPoolExecutor的方式来创建,而队列也不建议使用无界队列,而要使用有界队列,比如ArrayBlockingQueue。而拒绝策略这个就看你自己需求了(系统提供的如果不满足,就自己写一个)
同时对于核心线程数的设置也不是越大越好,只能说根据你的需求来设置这个值,一般来讲可以根据下面两点来进行合理配置
- 对于I/O密集型任务,可以将线程数设置大一点,比如 CPU个数 * 2
- 对于计算性任务(在内存中进行大量运算),可以将线程数设置小一点, 比如就等于 CPU的个数
当然啦,这个考虑是很多方面的,不仅仅和程序有关,还和硬件等资源有关,总之就是在测试的时候多多调试。
大家不要以为我上面说的是句废话,请你自信一点,把以为去掉。