现在要进厂,每个面试官都要问你熟不熟悉mysql,作为开发者咋们也应该清楚mysql的基础体系架构
![mysql架构]()
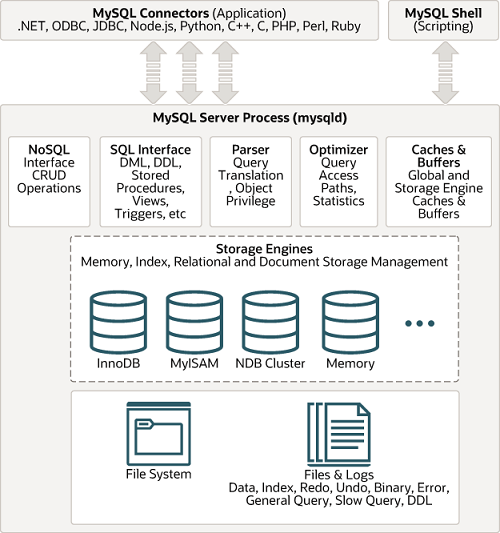
从Mysql官网提供的体系结构图中可以看出来出来,整个mysql分为以下几部分
- 连接池
- SQL接口组件
- 查询分析器组件
- 优化器组件
- 缓存组件
- 存储引擎(插件)
- 物理文件
mysql比较有特色的一点就是,它的存储引擎是以插件方式提供的, 而每个存储引擎决定了我们的数据是如何存放的。
虽然存储引擎有很多种,但是我们常用的不太多。 比如我就只使用过 InnoDB,MyISAM,Memory,InfoBright这4种。
MyISAM VS InnoDB
- MyISAM不支持事务(不支持ACID),InnoDB支持事务(支持ACID)
- 使用DML语句时,MyISAM锁级别是表锁,同一时间只支持一个session修改表,而InnoDB是行锁,粒度更细,并发更高
- MyISAM不支持外键,InnoDB支持
- MyISAM写入速度慢,查询速度快,InnoDB写入快,查询慢(相对)
- InnoDB因为支持事务,所以更可靠,MyISAM无法保证数据完整性
- MyISAM只存储索引,不缓存数据,支持全文索引,InnoDB缓存索引以及数据,不支持全文索引(5.6之前)。
所以在选择哪个引擎的时候要根据实际业务选择,比如某个业务只会插入一次数据,后面的都只有查询,那么我就建议使用MyISAM,如果需要支持事务那就用InnoDB。
InnoDB引擎
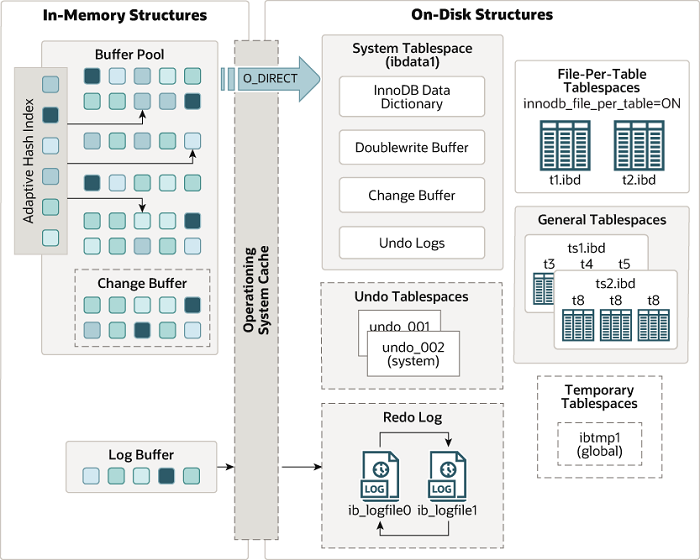
由于我们平时使用最多的还是InnoDB引擎,所以这里主要剖析下InnoDB的存储结构(MyISAM和InnoDB在存储结构上是类似的)
![InnoDB索引引擎(5.7)]()
5.7和8.0有些许不一致,主要是系统表空间的一些内容会移动到单独的表空间中去
为了保证数据不丢失,我们的数据必须要落盘,但是如果每次增删改查都去操作磁盘,那效率太低了,所以mysql会在内存中抽象出一份数据结构和磁盘一一对应,这样我们每次的增删改查就会优先操作内存中的数据。
咱们插入的数据是存储在磁盘的,而平时我们通过Navicate或者shell查询出来的数据,展现形式为表格,并不代表我们的数据也是这样直接这样存储在磁盘上的,磁盘上的数据有自己的格式。
比如我们将数据存在在文件是这样存储的
1
2
3
| user.id=1
user.name=think123
user.age=18
|
在我们代码中,我们会将其映射为一个java对象
1
2
3
4
5
6
| public class User {
private Long id;
private String name;
private Integer age;
}
|
输出显示的时候又是这样
1
2
3
4
5
| {
"id": 1,
"name": "think123",
"age": 18
}
|
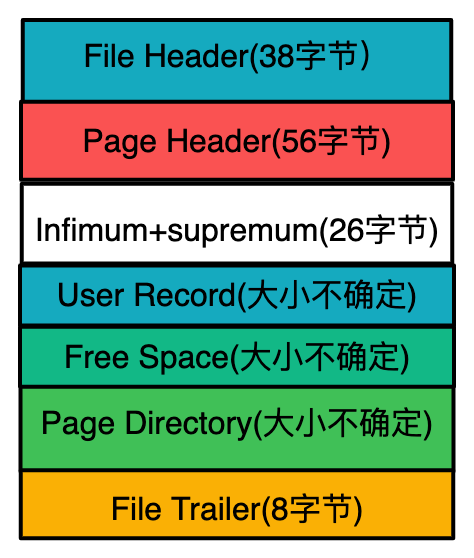
内存结构
将内存中数据刷新到磁盘并不是一条数据一条数据从内存刷新到磁盘的,为了效率,InnoDB将数据划分为若干个页,以页作为磁盘和内存之间交互的基本单位,InnoDB中页的⼤⼩⼀般为 16KB,和磁盘上默认的页大小一致。也就是在⼀般情况下,⼀次最少从磁盘中读取16KB的内容到内存中,⼀次最少把内存中的16KB内容刷新到磁盘中。
而内存数据结构主要分为 Buffer Pool(缓冲池) 和 Log Buffer(日志缓冲),它们管理的都是页,而页中存储的是数据。
Buffer Pool(缓冲池)
Buffer Pool中存储的是页,页中会存储很多条数据。当我们修改数据的时候会先修改内存中的数据,修改后的页面并不立即同步到磁盘,而是作为脏页继续呆在内存中,然后会有后台线程将内存中的数据刷盘到文件,保证数据一致。
![简化的结构]()
我们可以通过下面的命令查看缓冲池大小
1
| show VARIABLES like 'innodb_buffer_pool_size'
|
如果要修改,则通过修改配置完成
1
2
| [server]
innodb_buffer_pool_size = 268435456
|
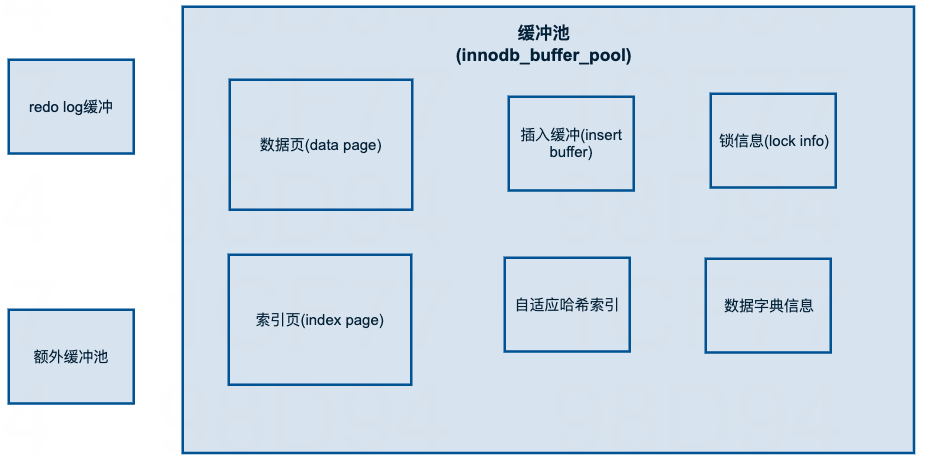
缓冲池中缓存的数据页类型有:索引页、数据页、undo页、修改缓冲(change buffer)、自适应哈希索引(adaptive hash index)、InnoDB中锁信息、数据字典信息等。除了这些,InnoDB引擎中内存的结构除了缓冲池还有其他结构,如图所示
![InnoDB内存数据对象]()
图中插入缓冲的部分现在叫做修改缓冲(change buffer),也就是说以前只对插入有用,现在对insert update delete都起作用,后面会分析下什么是修改缓冲
多线程环境下,访问缓冲池(buffer pool)中的各种page是需要加锁的,不然会有并发问题,而且在Buffer Pool特别⼤⽽且多线程并发访问特别 ⾼的情况下,单⼀的Buffer Pool可能会影响请求的处理速度。所以在Buffer Pool特别⼤的时候,我们可以把它们拆分成多个⼩的Buffer Pool,每个Buffer Pool都称为⼀个实例,它们都是独⽴的,独 ⽴的去申请内存空间,这样可以增加数据库的并发处理,减少资源竞争,我们可以通过修改配置的方式来配置缓冲池个数
1
2
| [server]
innodb_buffer_pool_instances = 2
|
每个buffer pool占用内存空间就是
1
| innodb_buffer_pool_size/innodb_buffer_pool_instances
|
自适应Hash索引
Mysql中B+树的索引高度一般为3-4层,因此需要3-4次的查询,InnoDB会监控表上各索引页的查询,如果建立hash索引可以带来性能提升,则会建立hash索引,称之为自适应哈希索引(Adaptive Hash Index, AHI),AHI通过缓冲池的B+树页构造而来,而且并不需要对整张表建立hash索引,只是对热点页建立hash索引。
AHI要求对某个页的连续访问模式一样,比如对于(a,b)这样的联合索引页,存在下面两种情况
1
2
| where a = xxx;
where a = xxx and b=xxx
|
如果每次都查询条件一样,但是交替出现上面两种查询,那么InnoDB不会建立Hash索引,如果只出现一个查询,然后再满足下面的要求,InnoDB就会建立自适应Hash索引
- 以该模式(同样的等值查询条件)访问了100次
- 页通过该模式访问了N次,N = 页记录/16
这种索引属于数据库的自优化,无需DBA进行认为调整。我们可以通过下面的命令查看当前自适应hash索引的使用情况。
1
| show engine innodb status;
|
其本质是将频繁访问数据页的索引键值以“Key”放在缓存中,“Value”为该索引键值匹配完整记录所在页面(Page)的位置,通过缩短寻路路径(Search Path)从而提升MySQL查询性能的一种方式
物理结构
数据最终会落盘到磁盘的文件中,而实际mysql管理的数据以及额外信息等等都会写入到文件中。
系统表空间
InnoDB采用将存储的数据按照表空间(tablespace)进行存放设计,默认配置下会有一个初始大小为10M,名为 ibdata1的文件,这个文件就是系统表空间文件,我们可以通过参数在配置文件中进行设置,比如:
1
| innodb_data_file_path = ibdata1:10M:autoextend
|
表示文件初始大小为10MB,用完了这10M,该文件可以自动增长(autoextend)。
设置 innodb_data_file_path 参数后,所有基于InnoDB存储引擎的表的数都会记录到该共享表空间中。
系统表空间中除了双写缓冲区(doublewrite buffer)、change buffer、undo logs之外,还会记录一些有关整个系统的信息。
再次提一下,从mysql 8.0开始doublewrite buffer会有单独的文件, undo log也会放到自己单独的表空间中
https://dev.mysql.com/doc/refman/8.0/en/innodb-architecture.html
当我们插入数据到表里面的时候,我们需要知道很多信息,比如
- 某个表属于哪个表空间,表里面有多少列
- 表对应的每一个列类型是什么
- 该表有多少索引,每个索引对应哪些字段,该索引对应的根页面在哪个表空间的哪个页面
- 该表又哪些外键,外键对应哪个表的哪些列
- 某个表空间对应文件系统上文件路径是什么
等等。
上面提到的这些数据实际和我们插入数据无关,但是为了更好管理我们的用户数据而不得不引入的额外数据被称为元数据。InnoDB特意定义了一系列的内部系统表用来记录这些数据,不过咱们是不能直接访问InnoDB的这些内部系统表的,除⾮直接去解析系统表空间对应⽂件系统上的⽂件。
好在我们可以在infomation_schema数据库中看到这些表数据
- INNODB_SYS_COLUMNS: 整个InnoDB存储引擎中所有的列的信息
- INNODB_SYS_DATAFILES: 整个InnoDB存储引擎中所有的表空间对应⽂件系统的⽂件路径信息
- INNODB_SYS_FIELDS: 整个InnoDB存储引擎中所有的索引对应的列的信息
- INNODB_SYS_FOREIGN: 整个InnoDB存储引擎中所有的外键的信息
- INNODB_SYS_FOREIGN_COLS: 整个InnoDB存储引擎中所有的外键对应列的信息
- INNODB_SYS_INDEXES: 整个InnoDB存储引擎中所有的索引的信息
- INNODB_SYS_TABLES: 整个InnoDB存储引擎中所有的表的信息
- INNODB_SYS_TABLESPACES: 整个InnoDB存储引擎中所有的表空间信息
- INNODB_SYS_TABLESTATS: 整个InnoDB存储引擎中所有表统计信息
- INNODB_SYS_VIRTUAL: 整个InnoDB存储引擎中所有的虚拟⽣成列的信息
information_schema数据库中的这些以INNODB_SYS开头的表并不是真正的内部系统表,⽽是在存储引擎启动时读取真正的系统表,然后 填充到这些以INNODB_SYS开头的表中。
独立表空间
当我们在数据库新建一个表test的时候(如果未做特殊说明,表引擎都是InnoDB),会产生两个文件,一个是 test.frm文件,一个是test.ibd文件。
frm文件中存储的是表结构(任何存储引擎都会产生这个文件),ibd文件存储的是索引以及数据。
如果设置了 innodb_file_per_table ,则每个基于InnodDB存储引擎产生的表都会产生一个独立表空间,其命名规则为 表名.ibd。
表空间是⼀个抽象的概念,对于系统表空间来说,对应着⽂件系统中⼀个或多个实际⽂件;对于每个独⽴表空间来说,对应着⽂件系统中⼀个名为 表名.ibd 的实际⽂件
innodb_file_per_table 也是推荐的方式(我使用的5.7默认是开启的),可以通过以下命令查看设置情况
1
| show VARIABLES like 'innodb_file_per_table'
|
需要注意的是单独的.ibd独立表空间文件仅仅存储该表的数据、索引和插入缓冲等信息,其余信息还是存放在默认的系统表空间中的。
通用表空间(general tablesapce)
通用表空间是使用 CREATE TABLESPACE 语法创建的共享 InnoDB 表空间,我们除了像上面那样说的让每个表都有自己的独立表空间之外,还可以让多个表在同一个表空间
1
2
3
4
5
6
7
8
9
| // 创建表空间,文件默认是在data目录下
CREATE TABLESPACE `ts1` ADD DATAFILE 'ts1.ibd' Engine=InnoDB;
// 可以放到data目录外
CREATE TABLESPACE `ts1` ADD DATAFILE '/my/tablespace/directory/ts1.ibd' Engine=InnoDB;
// 指定表在某个表空间
CREATE TABLE t1 (c1 INT PRIMARY KEY) TABLESPACE ts1;
|
这个让多个表在同一个表空间有啥用呢? 按照官方文档的说法,其主要特殊点在于两个地方
- 相比独立的表空间,通用表空间因为是多个表放到同一个表空间中,所以其元数据占用内存更少
- 通过表空间可以将数据文件放在MySQL数据目录之外,因此我们可以为这些特定的表设置RAID或DRBD,或将表绑定到特定的磁盘上
临时表空间(temporary tablespace)
临时表空间分为会话(session)临时表空间和一个全局(global)临时表空间。
全局临时表空间在正常关机或初始化中止时被移除,并在每次服务器启动时重新创建。全局临时表空间在创建时收到一个动态生成的空间ID。如果全局临时表空间不能被创建,则拒绝启动。如果服务器意外停止,全局临时表空间不会被删除。在这种情况下,数据库管理员可以手动删除全局临时表空间或重新启动MySQL服务器。重启MySQL服务器会自动删除并重新创建全局临时表空间。
会话临时表空间在第一次请求创建磁盘临时表时从临时表空间池中分配给会话。 一个会话最多分配两个表空间,一个用于用户创建的临时表,另一个用于优化器创建的内部临时表。 分配给会话的临时表空间用于会话创建的所有磁盘临时表。 当会话断开连接时,其临时表空间将被截断并释放回池中。
当我们创建临时表的时候数据会被放到临时表空间
session的临时表数据会存储在ibt文件中,而global session的临时表数据会存储在ibtmp1文件中
临时表可以使用各种引擎类型,如果使用的是InnoDB或者MyISAM引擎的临时表,写数据的时候是写到磁盘上的,当然临时表也可以使用Memory引擎。
临时表只针对当前会话有用,当会话(session)被关闭的时候,这个临时表也会被删除。临时表具有以下特性
- 临时表只能被创建它的session访问,对其他线程不可见。
- 临时表可以于普通表同名
- session A中有同名的临时表和普通标表的时候,show create 语句,以及增删改查语句访问的是临时表
- show tables不显示临时表
redo log
我们之前说过修改数据也是先修改buffer pool中页的数据,如果事务提交后发生了故障,导致内存中的数据都丢失了(此时还未刷盘),那提交了的事务对数据库所做的更改也跟着丢失了,这是不能忍受的。
为了保证事务持久性(对于一个已经提交的事务,在事务提交后,即使系统发生了崩溃,这个事务对数据库中所做的更改也不能丢失),我们必须要有一个机制来记录事务到底修改了什么内容。
如果每次修改了buffer pool中数据就刷盘到磁盘的话,是不可取的,原因有2个。
- 刷新一个完整的数据也太浪费了: 可能只更新了一个页的几个字节,但是确要刷整个页
- 随机IO比较慢: 一个事务可能更新多个页,如果这些页不连续,就会产生很多随机IO,随机IO比顺序IO要慢。
因此我们使用redo log记录更新了什么内容,当事务提交时,我们只需要把redo log内容刷到磁盘中,即使系统崩溃了,我们也能根据文件内容恢复。使用redo log有以下优势
- redo日志占用空间非常小
- redo日志是顺序写入磁盘的: 每次执行一条语句就可能产生多条redo日志,这些日志是按照产生顺序写入的
默认情况下,InnoDB存储引擎的数据目录下会有两个名为 ib_logfile0 和 ib_logfile1 的文件,这个文件是redo log file,它们记录了InnoDB存储引擎的redo日志。
当mysql发生问题时,比如断电了,InnoDB引擎会使用redo log恢复到掉电前时刻,以此来保证数据完整性。
写入redo log并不是直接写,而是先写入redo log buffer中,然后再写入到日志文件中,写入方式是循环写入,InnoDB先写重写ib_logfile0,当文件1达到文件最后时,会切换至ib_logfile1,当文件2也被写满时,会在切换到文件1,如此循环往复。
同样的这里有两个参数可以控制redo log
1
2
3
4
5
6
7
8
9
| #查看相关配置
show VARIABLES like 'innodb%log%'
#指定日志文件大小
innodb_log_file_size=5M
#指定文件组个数(默认值是2,所以是ib_logfile0,ib_logfile1两个文件)
innodb_log_files_in_group=2
|
看到这里是不是会疑惑,先写入redo log buffer,在刷盘,如果在刷盘的时候系统也崩溃了,不是也没办法回复数据吗?那再加一层来解决? 这不就是俄罗斯套娃了么
还好mysql没有这么干,它让我们可以选择修改⼀个称为 innodb_flush_log_at_trx_commit 的系统变量的值,该变量有3个可选的值
- 0:当该系统变量值为0时,表⽰在事务提交时不⽴即向磁盘中同步redo⽇志,这个任务是交给后台线程做的。 这样很明显会加快请求处理速度,但是如果事务提交后服务器挂了,后台线程没有及时将redo⽇志刷新到磁盘,那么该事务对页⾯的修改会丢失。
- 1:当该系统变量值为1时,表⽰在事务提交时需要将redo⽇志同步到磁盘,可以保证事务的持久性。1也是innodb_flush_log_at_trx_commit的默认值。
- 2:当该系统变量值为2时,表⽰在事务提交时需要将redo⽇志写到操作系统的缓冲区中,但并不需要保证将⽇志真正的刷新到磁盘。 这种情况下如果数据库挂了,操作系统没挂的话,事务的持久性还是可以保证的,但是操作系统也挂了的话,那就不能保证持久性了。
参考资料
- Mysql官方文档
- <<MySQL是怎样运行的:从根儿上理解MySQL>>
- <<MySQL技术内幕:InnoDB存储引擎>>