·
工作8年,你就是这样记日志的?
平常在写代码的过程中,我们经常需要记录日志,具体的日志实现我们可以使用logback, log4j, log4j2等。 但是一般我们会通过日志门面来记录日志,比如通过SLF4J或者apache commons logging。 无论使用哪种方式记录日志都不在我们这篇文章的讨论范围内。
如果你对它们如何找到真正的日志实现感兴趣,可以看看我之前的文章。
日志怎么记录
日志分为6种,每种级别实际上有不同的应对场景,但是说实话我在项目中看到最多的永远是INFO, ERROR级别。
几乎没有怎么见到业务系统中有其他级别。 DEBUG的日志在集成的各个框架中是比较多见的。
日志应该是帮助我们定位问题的,所以日志怎么记录其实很关键。
SpringBoot中使用profile的几种方式
最近项目中进行仓库拆分了之后,因为引入了公共包,所以就存在可能有snapshot版本以及release版本问题,比如我想要在dev环境的时候import snapshot版本,prod环境的时候又使用release版本,为了不频繁修改pom.xml文件,因此决定使用POM的profile来解决这个问题。
当然由于maven默认是不下载snapshot包的,因此我们要配置让它下载,这里分为全局配置和项目级别配置
项目配置
在pom文件中添加如下内容
1 | <repositories> |
Git中仓库拆分的两种方式
最近要把项目中的子模块单独拆分为一个项目,并且移动到新的仓库地址,同时需要保留所有提交记录以及所有分支(包括未上线-未合并到master分支)的代码,我这里总结了2种方式以供大家参考。
项目现状
1 | bv_sc_server |
<!-more–>
项目中有很多子模块,我需要将他们单独独立出来放到放到一个新的仓库,同时只保留各自仓库的代码。
比如我有一个分支feature/migrate-data,它同时修改了bvpro-file以及bvpro-job的代码,那么迁移过去的效果希望是
新的bvpro-file和bvpro-job仓库都有这个分支,同时也只包含当前仓库的代码,而不再想之前一样混杂着多个模块的代码。
因此调研了下发现有两种方案可以达到这样的目的,一种是git subtree, 一种是git filter-repo。
git subtree
需要拆分的仓库叫做 bv_sc_server, 现在需要拆分的模块是 bv_sc_server/bvpro-modules/bvpro-job, 拆分后的新仓库叫做bvpro-job
先在代码服务器(比如gitlab)上新建一个空的仓库, 比如bvpro-job
在本地文件夹clone刚创建的新仓库, 和bv_sc_server在同一个目录下
1 | git clone http://localhost:8090/sc_group/bvpro-job.git |
- 进入bv_sc_server这个仓库的目录下进行拆分,当前处于master分支(这个分支是需要迁移的分支)
1 | git subtree split -P bvpro-modules/bvpro-job -b feature/split-bvpro-job |
- 进入到bvpro-job这个新仓库,执行以下命令:
- cd ../bvpro-job
- git pull ..\bv_sc_server feature/split-bvpro-job
- git remote remove origin
- git remote add origin http://localhost:8090/sc_group/bvpro-job.git
- git push –set-upstream origin –all
到这里我们就把bv_sc_server中bvpro-job模块的master分支代码迁移到了新的仓库,但是其他分支还没有迁移过去,所以这里我们重复执行下操作
这里为了不相互影响,我们将本地bvpro-job目录删除,然后重新新建一个空白bvpro-job目录。然后在重复执行上面的命令,这里为了演示方便我就将命令写到一起。
1 | cd bvpro-job |
这样就完成了feature/SCA-5034_AutoApprovalForTcAndSc分支的迁移了,这样迁移也只保留了bvpro-job有关的代码,如果这个分支在以前的其他模块也有代码,那么也要按照这样的方式进行迁移,同时有多少个分支需要迁移就需要执行多次上面的命令。
可以发现这样迁移的效率是很低的,要是分支或者提交记录很多一天的时间都耗在这上面了。当然如果你只想要迁移master分支代码,这种方式也是很不错的,关键是这个命令是git自带的。
git filter-repo
这个命令并不是git自带的,但是它也很赫赫有名,毕竟官方都推荐使用它进行迁移。
使用它是有限制的,首先python版本要在3.5以上,git版本要在2.2以上。因为我使用的是windows,所以下面演示windows上的安装方式
- 安装git-filter-repo
1
python -m pip install --user git-filter-repo
记录下安装的地址,然后配置环境变量,然后就可以使用git filter-repo这个命令了。
- git clone bv_sc_server项目,默认master分支,最好是最新的,这样子命令运行错了也不影响你的开发
1 | git clone http://localhost:8090/sc_group/bv_sc_server.git bvpro-job |
- 拆分
1 | cd bvpro-job |
上面的命令执行完成后,bv_sc_server这个目录下的代码就只有以前bvpro-job的代码了
- 推送
1 | git remote add origin http://localhost:8090/sc_group/bvpro-job.git |
这样子就将bvpro-job这个子模块的所有代码,commit以及分支都迁移到了新的仓库,不用再想subtree一样针对特定的分支反复操作了, 所以我是推荐使用这个命令的。
好家伙,这些问题还不是手拿把掐
总结了下这段时间遇到的问题。
快速生成字典表数据
在前期开发的时候,BA总是给我好几张excel,让我生成字典表,写代码又耗时,而且不同的excel字段也不一样,不可能每次都要去改代码吧,总之我不干,好在我能借助excel函数完成这样的需求。
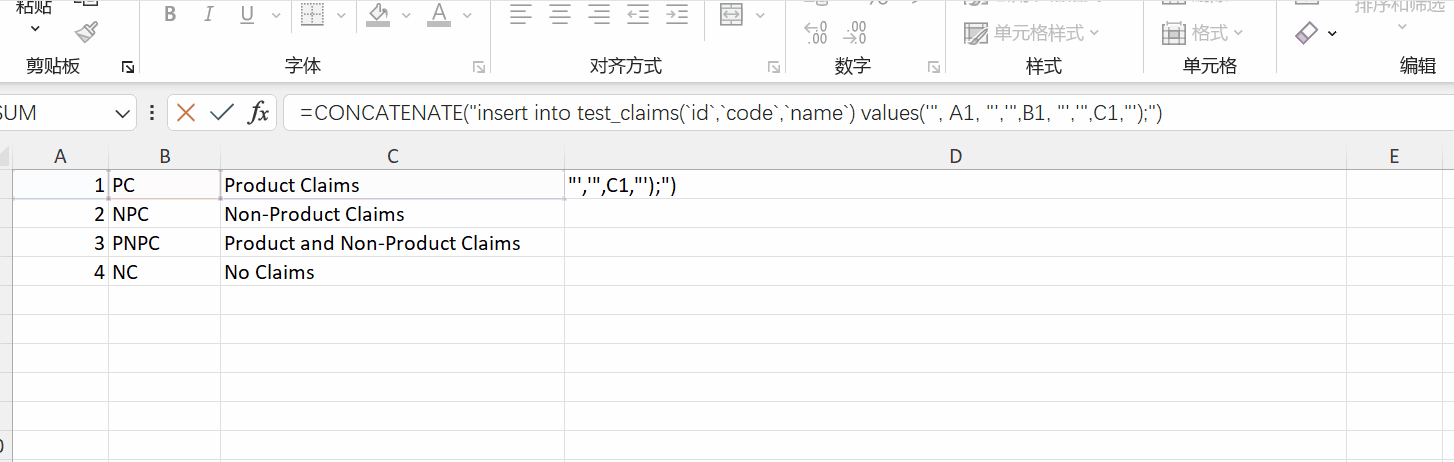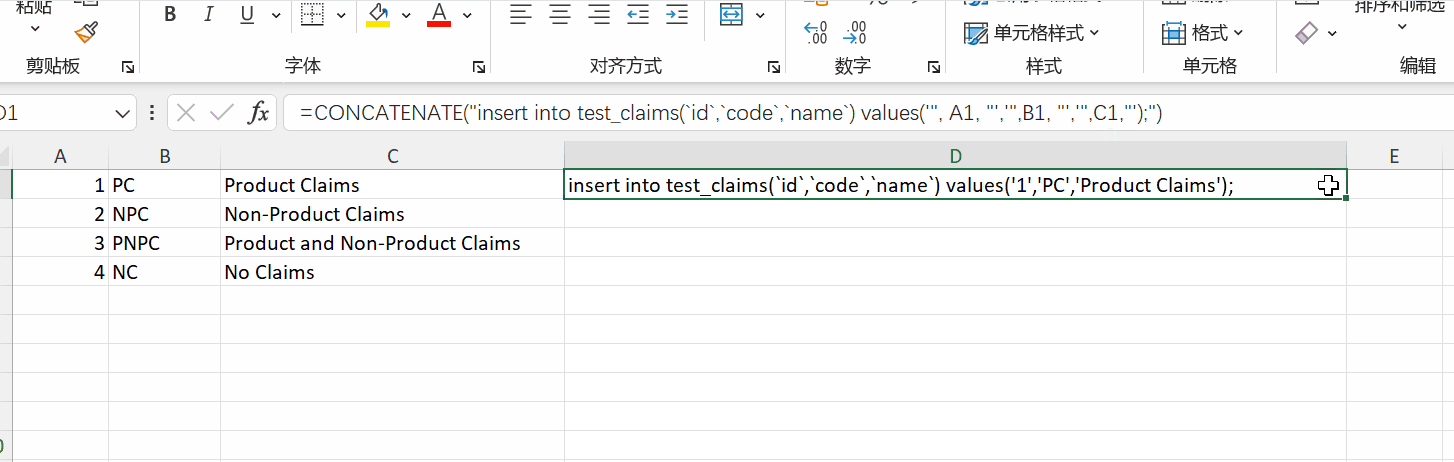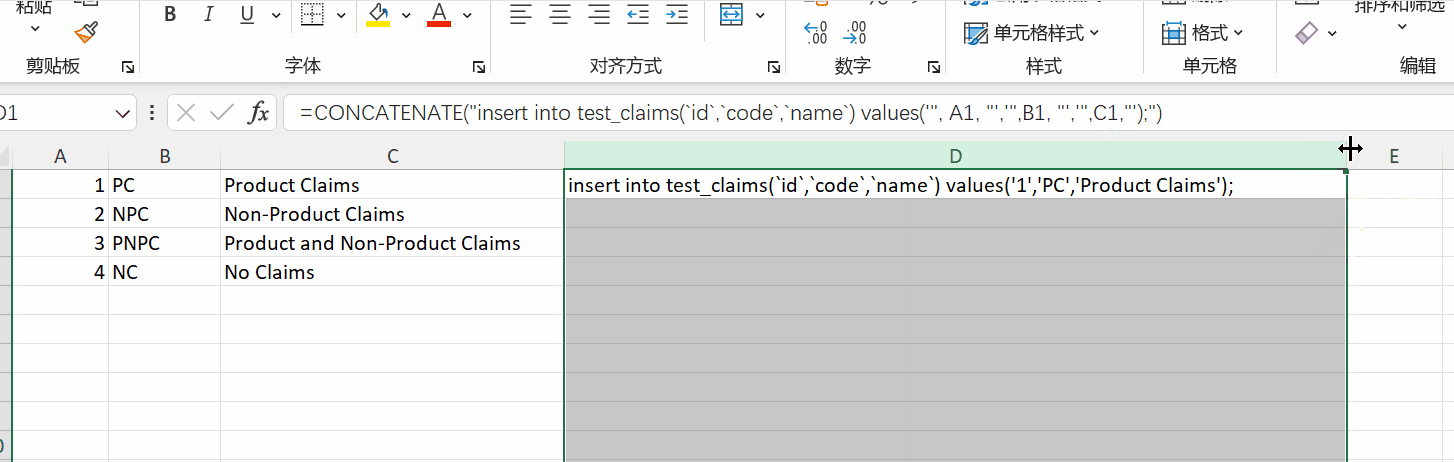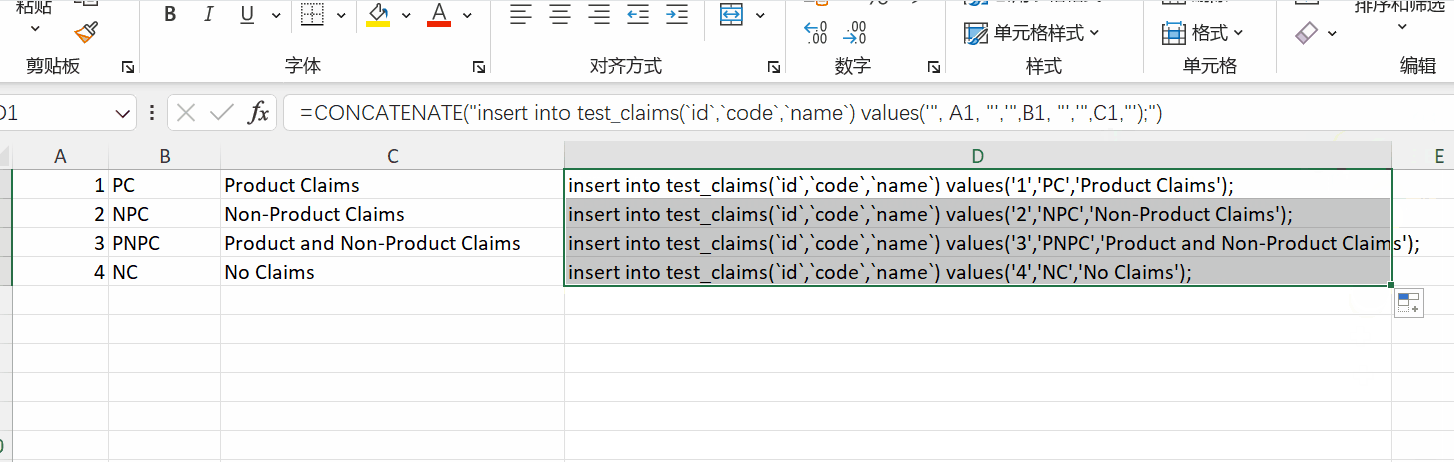
1 | =CONCATENATE("insert into test_claims(`id`,`code`,`name`) values('", A1, "','",B1, "','",C1,"');") |
Kubernetes Pod频繁重启
后台看到部署到kubernetes的pod一直在重启,但是看日志没有报错,但是一会儿它就自动重启了,最后通过describe命令看到是因为liveness接口的原因
1 | kubelet Liveness probe failed: Get "http://10.24.8.84:9202/actuator/health" |
因为使用了springboot actuator接口,它会检测服务中使用到的其他服务是否能正常使用,从而判定当前服务是否存活,所以必然是因为这个接口返回的信息导致pod重启。
重启的这个服务主要用到了邮件以及Redis,但是不知道到底是哪个服务健康检查失败了。此时我们也无法进入到pod中访问health接口了。
所以我们先移除掉pod template的livenessProbe配置,然后重新部署服务
1 | livenessProbe: |
这个时候使用exec命令进入pod
1 |
|
访问 curl -i http://localhost:9202/actuator/health 可以看到response status code是503,并且还可以看到具体失败的组件是哪一个。
最终确定是redis访问超时了,于是调整了下 livenessProbe的timeoutSeconds,然后在重启就不报错了。
1 | root@noti-844567c558-2mvj8:/home/pro# curl -i http://localhost:9202/actuator/health |
minio数据迁移到Azure blob
项目中需要将minio中保存的文件迁移到azure的blob中,然后minio中保存文件的路径是这样的 2023/11/07/20231107164256A579/Image3.jpg 相当于文件夹中包含了时间戳等信息,虽然blob不支持目录,但是它的虚拟目录可以有相同的效果,这里我们使用azure提供的azcopy命令来进行数据迁移。
首先进入到minio所在的服务器,然后执行下面的命令
1 |
|
总结
以上就是我最近遇到的问题,第一个字典表的那个当时第一反应是写代码,但是后来想到写代码的时候太长,成本太高还是需要借助工具,恰好提供给我的又是excel,于是就用excel顺带完成了这个功能,同时后面的其他字典数据如法炮制,也就变简单了。
第二个问题本来是定位重启的问题,但是看着看着就深入到了actuator的源码当中起了,这一点很不好,不过有失必有得,有顺带看了下actuator的源码,它其中的EntryPoint感觉很棒,后面针对这个写一篇。
第三个问题的话就是微软没有提供如何迁移的文档,不过好在它本生工具不少,多尝试也就成功了,这里我把迁移的步骤给出来,希望能帮助到同样有需求的人。
因为一个bug,我还是掀开了openfeign的神秘面纱
报错
最近项目中访问一个外部api报错了,报错信息如下
1 | PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find valid certification path to requested target |
看着像是证书问题,这个时候我首先想到的是百度下,看看怎么解决。
解决方案
百度告诉我说如果你open-feign中使用的是http client,那么可以通过下面的配置来让跳过SSL验证
1 | feign: |
结果还是报同样的错误。 于是我又百度,又重新找了一个解决方法,这次的方案是让我自己重写Client了,具体操作如下
1 |
|
这把我感觉要起飞了, 一切尽在掌握中,重新deploy,打开postman,测试测试我的接口。
测试后感觉好了但是看日志又没有完全好。 这个接口倒是不报错了,但是我调用内部服务给我报错了,比如我这里的内部服务名称叫做
pro-file, 就现在它没法根据我这个pro-file名字找到对应的IP了,从而导致我这个服务使用不了了。
百度误我!
求人不如求己
此刻我自信的打开了IDEA, 输入了类名 FeignAutoConfiguration , Spring Cloud关于某个组件的自动注入类大多是XXXConfiguration, 所以按照这么找准没错。
然后我有自信的把断点打在了这个部分 FeignAutoConfiguration:246
1 |
|
重新启动项目,好家伙断点没进来呀。 没进来的原因大概率可能是不满足条件,我赶紧看看这里对应的Conditional, 发现了我的代码中没有
设置feign.httpclient.enabled属性的值, 而且这里也没有设置havingValue, 根据源码可以知道, 如果没有设置havingValue, 那么这个属性的值会被和false进行比较
1 | //org.springframework.boot.autoconfigure.condition.OnPropertyCondition.Spec#isMatch |
搞半天这个Configurtion相当于没起作用。
好好好,这么玩是吧。
既然这个配置不生效,那肯定有其他配置生效,我就找找其他配置,最终我在spring-cloud-openfeign-core这个jar包的loadbalancer这个包下面找到了我想要的配置
1 |
|
因为我们项目是采用springcloud alibaba进行开发,所以引入了spring-cloud-loadbalancer这个包,因此这个这个配置类就会生效,由于我们没有配置使用httpclient,同样也未使用okhttp,所以生效的配置类只有一个,那就是 DefaultFeignLoadBalancerConfiguration
这个配置类中retryClient会被加载,因为我们引入了spring-retry.
1 |
|
这也是为什么上面我们自己配置了自己的Client后,访问其他spring cloud服务会找不到地址,这是因为默认的client不会去通过LoadBalancer去获取服务地址。
小插曲
期间debug的时候,还发现最终的Client的SeataFeignClient,我一看才发现某个公共包引入了Seata,但是没有使用Seata功能,然后Seata会把我们最终使用的FeignClient在给封装一次,所以后面我就把seata从项目中移除了。
解决方案
既然问题找到了,那么就好修改了,修改方式有两种,一种是创建自己的RetryableFeignBlockingLoadBalancerClient, 就把上面的代码拿过来抄一遍,只是自己指定SSLContext,另一种是启用httpclient
方案一
1 |
|
方案二
另一种方案就是启用httpclient,并且禁用ssl验证,配置如下
1 | feign: |
自此这个问题解决了,当然在使用中更加倾向使用方案二,因为Feign默认的Client采用的是HttpURLConnection,它没有连接池,当然你也可以使用okhttp。
写到最后
这个问题看起来简单,但是排查起来还是颇费心思,很多细节隐藏到了框架之下,所以我想看源码还是有好处的,因为网上的文章别人的情况可能和你不一样,与其遨游在各个文章里面,还不如debug一把。
k8s中如何进行DNS解析
之前文章<老大喊我7天从SpringCloud转到K8S>中我提到过我们使用open-feign来访问内部服务,有很多童鞋留言问我访问内部服务的url应该怎么写,但是还是整个系统的整体url吗?
比如我整个系统的url是 http://www.think123.com, 现在有user服务和manage服务,那我现在想要访问user服务的ip就变成 http://www.think123.com/user吗? 当然不是因为这样的话你的访问就相当于还是访问外网,又要重新走gateway, 这样子不仅增加网络开销,而且我们做鉴权也不方便,因为服务间的访问鉴权往往是通过一个注解或者token来实现的。
<!-more–>
服务的ip地址
我们都知道在k8s中我们一般会部署多个pod, 而我们又是通过K8S的Service来做LoadBalance的,Service会根据一定的策略来选择具体访问的pod, 如下图所示
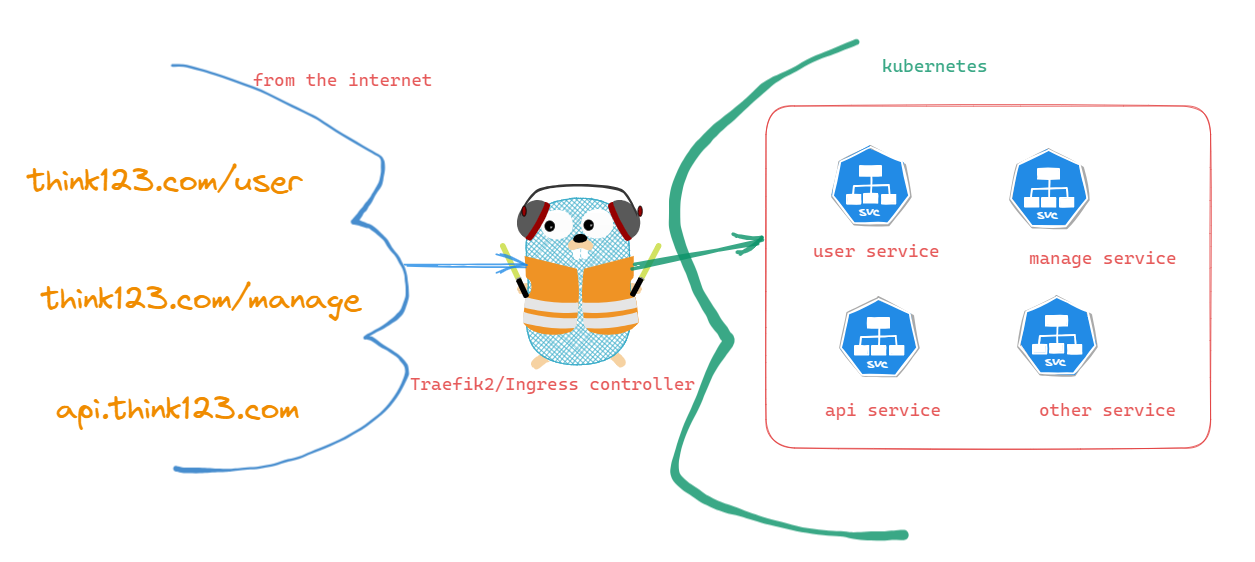
因此实际上我们只需要知道service的地址就行了,使用下面的命令查看service的地址
1 | kubectl get svc -n <namespace> |
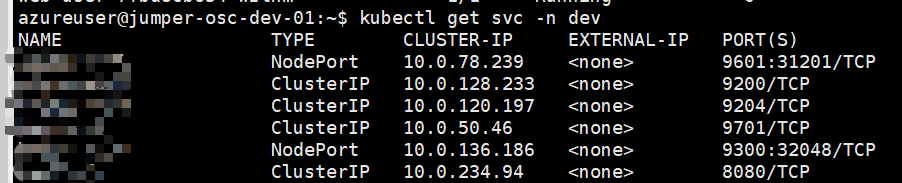
我们可以看到service的ip,因为我们服务是部署到同一个集群的,那是不是只需要知道服务的ip就行了,然后在open-feign中声明要访问的服务的ip加上端口就可以了呢?
原则是上可以的,但是实际上有问题,首先不同集群中ip地址不一样,如果你要部署不同集群,那么每次都要修改,其次就算只有一个集群,这个ip也是可能变动的,所以写ip不太靠谱。
服务的域名
好在kubernetes给某个服务都添加了一个域名(这是通过kube-proxy和iptables实现的), 域名的规则是 ..svc.cluster.local。
比如对于我们的user服务,我们这个地址就是 user.dev.svc.cluster.local(<serviceName>.<namespace>.svc.cluster.local)
当然后面的这么一堆你都可以省略,实际上我们在open-feign的url中只需要声明 http://user:9201/(服务名:端口) 就可以了,kubernetes在进行dns寻址的时候会先在本地dns找user这个域名对应的ip地址
K8S的DNS解析机制
集群域名和后缀:Kubernetes集群中的每个服务都会被分配一个域名,该域名由服务名称(Service Name)和命名空间(Namespace)组成。例如,一个服务名为my-service,位于命名空间my-namespace的服务的完整域名将是my-service.my-namespace.svc.cluster.local。svc.cluster.local是Kubernetes集群默认的后缀。
Kubernetes DNS服务器:Kubernetes集群内部有一个专用的DNS服务器负责处理服务的DNS解析请求。这个DNS服务器通常被命名为kube-dns或coredns。
解析流程:在进行DNS解析时,应用程序或服务可以使用服务名作为主机名(hostname),然后发送DNS查询请求到Kubernetes DNS服务器。
DNS查询:Kubernetes DNS服务器接收到DNS查询请求后,会根据请求中的域名信息进行解析。它首先进行域名拆分,将服务名、命名空间和集群后缀分离开。
域名解析:Kubernetes DNS服务器会依次解析域名的各个部分。它首先解析命名空间,然后根据服务名在该命名空间下查找对应的Service资源。
Service资源解析:Kubernetes DNS服务器在Service资源中查找与请求的服务名和命名空间匹配的条目。如果找到匹配项,将返回与之关联的Pod IP地址列表。
IP地址返回:Kubernetes DNS服务器将解析到的Pod IP地址返回给发起请求的应用程序或服务。
重试机制:如果在初始查询时没有找到匹配的Service资源,Kubernetes DNS服务器可能会进行一些重试机制,以确保服务名得到正确解析。这样做是因为在创建和删除Service资源的过程中,可能会存在一定的延迟。
通过这种方式,Kubernetes DNS解析机制使得服务能够通过服务名进行通信,无需关心具体的Pod IP地址。这种抽象层简化了服务之间的通信配置,并支持动态扩展和管理服务。
查看域名
可以通过下面的命令查看域名
1 | kubectl get svc my-service -n my-namespace -o jsonpath='{.metadata.name}.{.metadata.namespace}.svc.cluster.local' |
查看coredns
通过下面的命令可以查看coredns pod
1 | kubectl -n kube-system get pods -l k8s-app=kube-dns |
当然我们可以通过下面的命令查看coredns的配置
1 | kubectl -n kube-system get cm -l k8s-app=kube-dns |
其核心配置如下
1 | .:53 { |
.:53表示监听的 DNS 端口号为 53,. 表示根域名(Root Zone)。kubernetes cluster.local in-addr.arpa ip6.arpa定义了多个域和反向解析配置项。kubernetes是 Kubernetes 插件的名称,用于解析 Kubernetes 集群的服务和 Pod。cluster.local是 Kubernetes 集群内部域名的默认后缀。in-addr.arpa和ip6.arpa是用于反向 DNS 解析的 IPv4 和 IPv6 地址后缀。pods insecure允许对 Pod 进行非安全(insecure)的 DNS 解析。fallthrough in-addr.arpa ip6.arpa 表示如果查询未匹配到任何资源记录,则继续向下查询反向 DNS 解析。
forward . /etc/resolv.conf将未能解析的 DNS 请求转发给 /etc/resolv.conf 文件中配置的其他 DNS 服务器。
大家也可以去看pod中中/etc/host和/etc/resolv.conf然后也能发现一些迹象。
结束语
至此,讲清楚了集群中内部服务之间是如何访问的,且k8s是如何进行寻址导致对应的pod的,希望对大家有所帮助。
我在项目中这样使用状态机
最近一个新的项目中的一个业务,状态的流转比较复杂,涉及到二十几个状态的流转,而且吸取了其他业务教训,我们决定使用状态机来解决状态流转的问题。
要使用状态机除了自己写状态模式下还研究了当下两个开源项目,一个是spring的state machine,一个是cola-state-machine。
spring的状态机可以做状态持久化,和spring结合比较好,但是太重了。 cola就比较简单,它只是简单做了一个抽象,我们只需要实现具体的行为就行了。 使用cola最重要的就是要记得”因为某个事件,导致了状态A向状态B进行了迁移”,当然这里的状态可以是同一个。
因为项目中使用的是springboot,所以我这里结合起来做了一定的改造,下面给出我在项目中使用的例子,仅供大家参考
引入依赖
1 | <dependency> |
定义
因为某个事件,导致了状态A向状态B进行了迁移。所以需要定义状态,事件,流程。
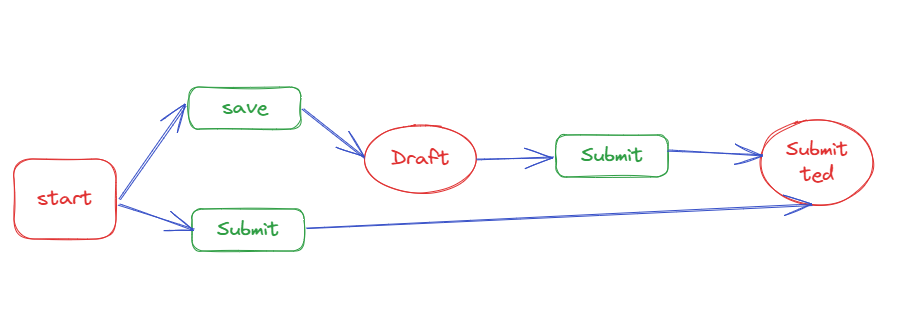
事件
根据我们的流程我定义了以下事件
1 |
|
状态
1 |
|
流程
定义状态迁移和事件的关系
1 |
|
使用Spring管理状态机
1 |
|
经过上面的定义后,后续有新的状态变更流程,我们只需要在 StatusChangeEnum 中添加就行了。
实现对应的handler
这里我举一个例子,比如说首次提交数据
1 |
|
这样子我们的每一个handler的功能就比较专一了,只需要处理对应状态的就行了,你可能回想要是有些状态的变成要做的事情类似,这样的代码不可能写两遍吧? 其实我们可以有一个抽象类可以将这些公用的逻辑放到抽象类里面,这样子有相同逻辑的就可以使用了。
使用
万事具备,现在只差在项目中使用了
1 |
|
只要涉及到状态变更的,就都可以调用StateMachie了。
写到最后
这种方式其实会导致类的数量变多,但是职责更加清晰,每个类的代码行数也并不多,而且以后想要找某个状态变更到某个状态做了什么时候很很好找。
这就是最近使用状态机的一些心得,希望能对你有所帮助。
helm常用命令
helm官方文档
hi, bro, 最好的永远是官方文档: https://helm.sh/zh/docs/
就是它上面的东西太多了,我知道你看得费力,所以我给你总结了下面的常用命令
helm添加仓库
1 | helm repo add elastic https://helm.elastic.co |
from-spring-cloud-to-springboot
之前项目使用的是springcloud,主要使用到的组件有 spring gateway, nacos, minio, load balancer,open-feign等,然后我们的微服务通过docker部署到虚拟机里面的。
但是出于安全的考虑,需要将它迁移到azure的aks(kubernetes)中,所以需要将spring cloud改造成spring boot。这样就不用自己维护虚拟机的安全策略,也不需要去关注补丁了。
梳理项目结构
项目是一个一个微服务组织起来的,大概业务类的服务有5个,公共服务有4个。 设计到的改造主要集中在gateway, auth中,公共包的一些改造比较少,主要是将open-feign的访问改为通过url进行调用,而不是之前通过服务名来。
而在kubernetes中,我们使用Traefik2来代替gateway的功能,不知道traefik2的,可以去翻翻之前的文章。
同时对于授权,需要提供一个授权接口,配合traefik2使用,这样每一个请求都会进行授权的验证。
开始改造
确定分支
最开始肯定是新拉一个分支进行这些改动,即便没改好也不影响其他人,所以我们先把分支名定好就叫做 feature/AKS-migrate。
改造gateway
首先把pom文件中的不需要的依赖包注释掉,比如spring cloud gateay, nacos, sentinel等spring cloud相关组件。注释掉之后
去看代码中有哪些报错,就针对性的修改。
我们的项目中使用蛮多gateway的filter以及handler,最开始我看他们都是使用的webflux,我就想我单独引入这个包,代码是不是最小的改动就行了呢?
这样尝试过之后我发现不行,因为项目中使用最多还是@RestController,如果使用webflux的方式,那么很多filter不生效的。
所以这种方式也不行,但是代码改得太多了,我只好回退到注释pom文件依赖的那一步。
没办法,只能读之前对应的代码逻辑,然后将其转换了。
读取gateway filter的代码,将其转换成spring filter,直接继承 org.springframework.web.filter.OncePerRequestFilter 即可,然后将之前的逻辑搬过来。
需要注意的是如果是全局filter需要放到公共包里面。
handler也是一样的,将其转换成filter,需要注意执行顺序。
这样,核心代码改造完毕,可以开启调试了
遇到的坑
处理上面说的webflux的问题外,将springcloud变成springboot后,我们之前的配置文件名称是bootstrap.yml,bootstrap-dev.yml文件,但是改成了springboot后,配置文件名要改成application.yml,application-env.yml。
不然你会发现你启动不了,说找不到文件,这个坑也是自己把自己给坑了。
然后就是要将gateway的filter转换成spring filter的时候要注意一定要保证之前的逻辑完全移植过来了,我就遇到一个在改造前可以重复读取request的流,但是改造后这段代码报错了,就是因为没有将这段逻辑移植过去的问题。
改造nacos
前面提到了nacos主要在open-feign的调用中以及变量注入中使用到了。feign那个好改,只需要指定url参数即可,这样就可以去掉nacos的依赖了。 然后变量注入同样的我们可以使用Kubernetes的ConfigMap以及Secret来代替。
所以我们需要将以前配置到nacos中的变量放到配置文件中,这样变量可以直接通过Kubernetes进行注入了。
我们在各个环境中只需要有一份代码(一个镜像),部署的时候只需要注入的配置不一样就可以了,这样就可以保证各个环境代码一致。
比如之前的配置是这样的
1 | spring: |
改造后配置文件的值为
1 | spring: |
而这里的变量是通过ConfigMap进行配置的,到时候会注入到容器环境变量中,这样spring就可以从环境变量中获取到值了。
部署
之前使用的jenkins方式部署,jenkins也是自己搭建的,现在全部迁移到了azure github上,所以这里直接使用azure的pipeline进行部署。 而我们管理k8s的资源则使用的是helm。
比如我项目中使用helm生成后结构如下
1 | C:. |
这里只需要部署的时候指定不同的value 文件,就可以实现同一个镜像部署到不同的环境了。
dev目录下config.yaml,secret.yaml文件内容大致如下:
1 | # config.yaml |
在template中configmap.yaml, secret.yaml中主要是如何将文件内容转换成对应的yaml
1 | #values.yaml 指定有哪些文件 |
最后给我deployment.yaml的例子,大家可以参考下
1 | apiVersion: apps/v1 |
至于values.yaml我就不给出来了,基本上是其他模板需要什么就写在上面就好了。
和Kustomize相比,helm安装第三方chart很方便,它有自己的仓库,这里附上我安装traefik2的命令
1 | # 添加traefiK仓库 |
本地验证
当你写好了上面的chart之后,如果你本地没有kubernetes环境(因为它可能在服务器才存在),而你又想要在本地进行验证你写得是否有问题,那么可以使用下面的命令。
1 | // 将下面的变量替换成你自己的。 chart-name表示chart的名字,chart-dir表示chart地址 |
然后如果你想要在k8s环境中安装的时候,而k8s环境又在远端服务器,那么你可以将chart打包,然后到服务器中进行安装,然后也可以在
将chart上传到服务器中,然后进行安装(服务器中要先安装helm)。
写到最后
自此,从springcloud迁移到k8s集群总算是完成了。因为是第一次使用helm(以前都用的kustomize),所以在helm这里耗费了一些功夫,主要是排查错误方面的,不过不得不说helm的文档写得不错,很清晰。
再然后就是代码改造以及一些配置问题,因为迁移azure,所以上面的关于它pipeline的一些配置不是很清楚,不过好在可以直接练习他们的运维,还是帮我们解决了一些问题的。