之前分析过AQS的源码,但只分析了独占锁的原理。
而刚好我们可以借助Semaphore来分析共享锁。
如何使用Semaphore
1 | public class SemaphoreDemo { |
Java SDK 里面提供了 Lock,为啥还要提供一个 Semaphore ?其实实现一个互斥锁,仅仅是 Semaphore 的部分功能,Semaphore 还有一个功能是 Lock 不容易实现的,那就是:Semaphore 可以允许多个线程访问一个临界区。
比较常见的需求就是我们工作中遇到的连接池、对象池、线程池等等池化资源。其中,你可能最熟悉数据库连接池,在同一时刻,一定是允许多个线程同时使用连接池的,当然,每个连接在被释放前,是不允许其他线程使用的。
比如上面的代码就演示了同时最多只允许3个线程访问API。
如何依托AQS实现Semaphore
1 | abstract static class Sync extends AbstractQueuedSynchronizer { |
Semaphore的acquire/release还是使用到了AQS,它把state的值作为共享资源的数量。获取锁的时候state的值减去1,释放锁的时候state的值加上1。
锁的获取
1 | public void acquire() throws InterruptedException { |
Semaphore也有公平锁和非公平锁两种实现,不过都是借助于AQS的,这里默认实现是非公平锁,所以最终会调用nonfairTryAcquireShared方法。
锁的释放
1 | public void release() { |
锁的释放成功后,会调用doReleaseShared(),这个方法后面会分析。
获取锁失败
当获取锁失败后,新的线程就会被加入队列
1 | public final void acquireSharedInterruptibly(int arg) |
当锁的数量小于0的时候,需要入队。
共享锁调用的方法doAcquireSharedInterruptibly()和独占锁调用的方法acquireQueued()只有一些细微的区别。
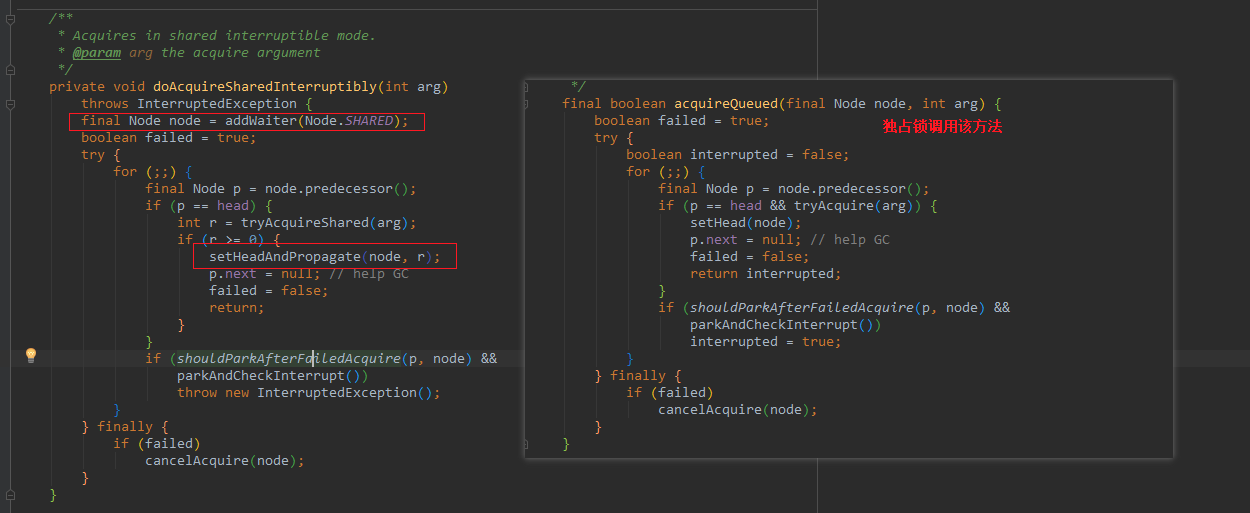
首先独占锁构造的节点是模式是EXCLUSIVE,而共享锁构造模式是SHARED,它们使用的是AQS中的nextWaiter变量来区分的。
其次在在准备入队的时候,如果尝试获取共享锁成功,那么会调用setHeadAndPropagate()方法,重新设置头节点并决定是否需要唤醒后继节点
1 | private void setHeadAndPropagate(Node node, int propagate) { |
其实看到这里就有一些逻辑我看不懂了,比如setHeadAndPropagate()方法中的这一段逻辑
1 | if (propagate > 0 || h == null || h.waitStatus < 0 || |
写成这样不好吗?
1 | if(propagate > 0 && h.waitStatus < 0) |
为什么要那么复杂呢?而且看上去这样也可以嘛,我本来想要假装看懂的,可是我发现骗自己真的不容易呀。
这里应该是有什么特殊的原因,不然Doug Lea老爷子不会这么写。。。。。。
PROPAGATE状态有什么用?
我就去网上搜索了下,结果在Java的Bug列表中发现是因为有一个bug才这样修改的
https://bugs.java.com/bugdatabase/view_bug.do?bug_id=6801020
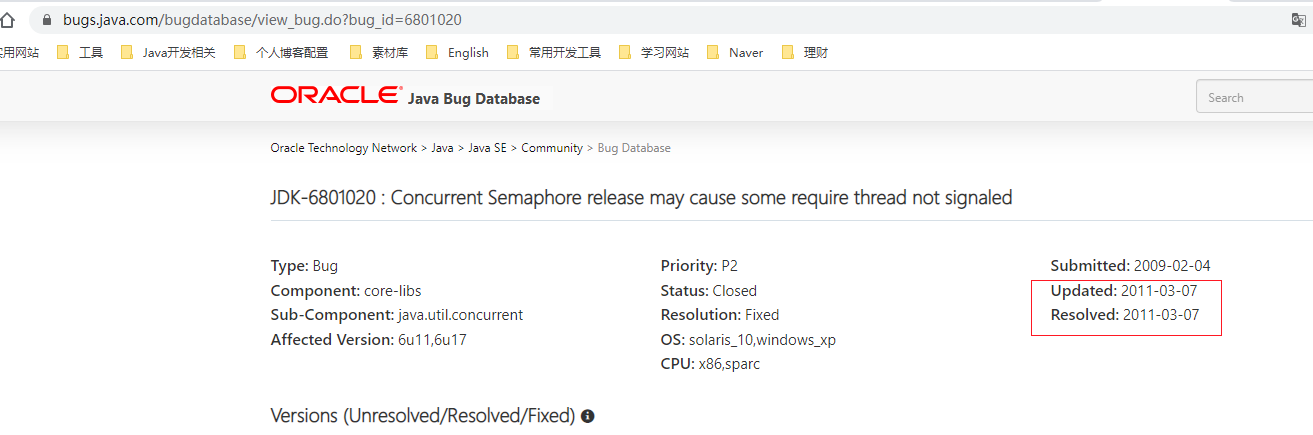
看到这个bug在2011年就在JDK6中被修复了,我想说那个时候我还不知道java是啥呢。。。。
这个修改可以在Doug Lead老爷子的主页中找到,通过JSR 166找到可对比的CSV,对比1.73和1.74两个版本
我们先看看setHeadAndPropagate中的修改对比
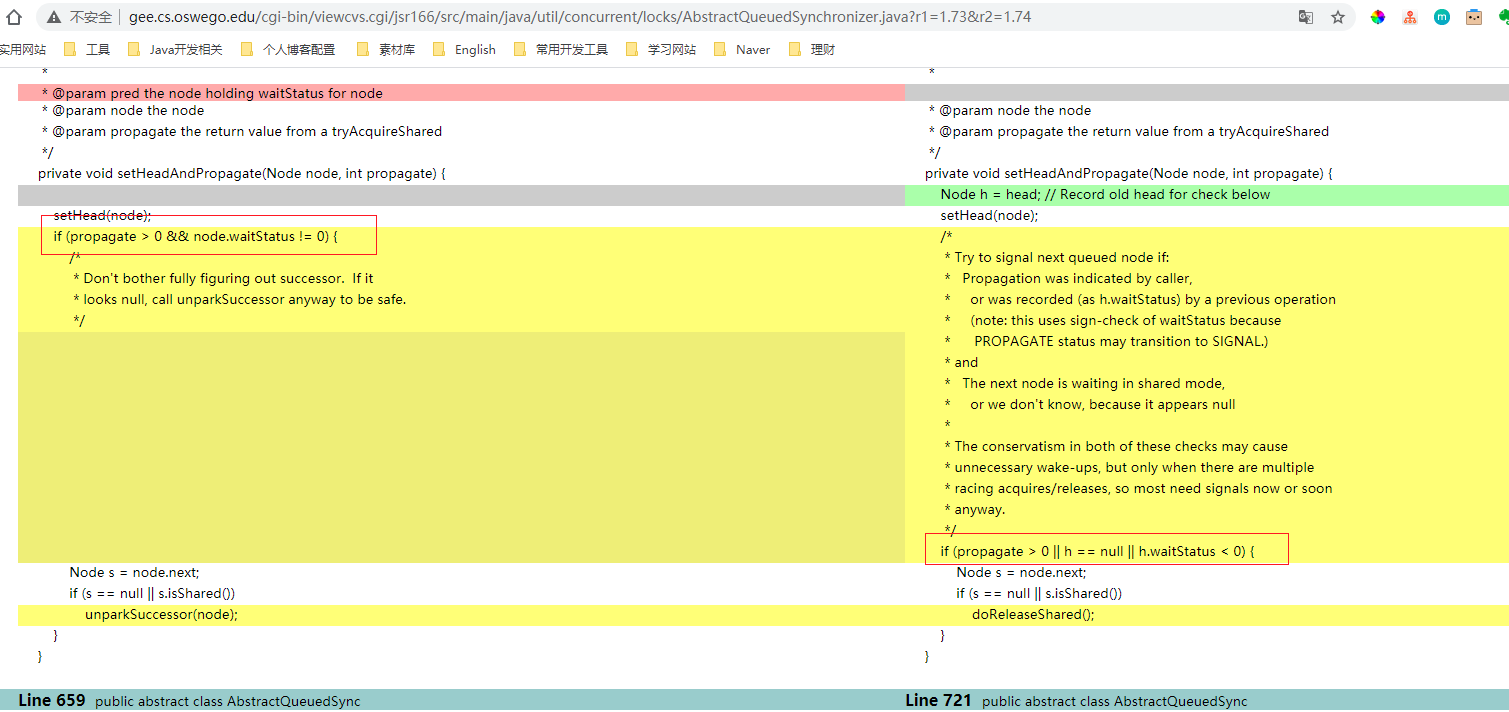
以前的版本中判断条件是这样的
1 | if (propagate > 0 && node.waitStatus != 0) |
这样的判断很符合我的认知嘛。但是会造成怎样的问题呢?按照bug的描述,我们来纸上谈兵下没有PROPAGATE状态的时候会出什么问题。
首先 Semaphore初始化state值为0,然后4个线程分别运行4个任务。线程t1,t2同时获取锁,另外两个线程t3,t3同时释放锁
1 | public class TestSemaphore { |
根据上面的代码,我们将信号量设置为0,所以t1,t2获取锁会失败。
假设某次循环中队列中的情况如下
1 | head --> t1 --> t2(tail) |
锁的释放由t3先释放,t4后释放
时刻1: 线程t3调用releaseShared(),然后唤醒队列中节点(线程t1),此时head的状态从-1变成0
时刻2: 线程t1由于线程t3释放了锁,被t3唤醒,然后通过nonfairTryAcquireShared()取得propagate值为0
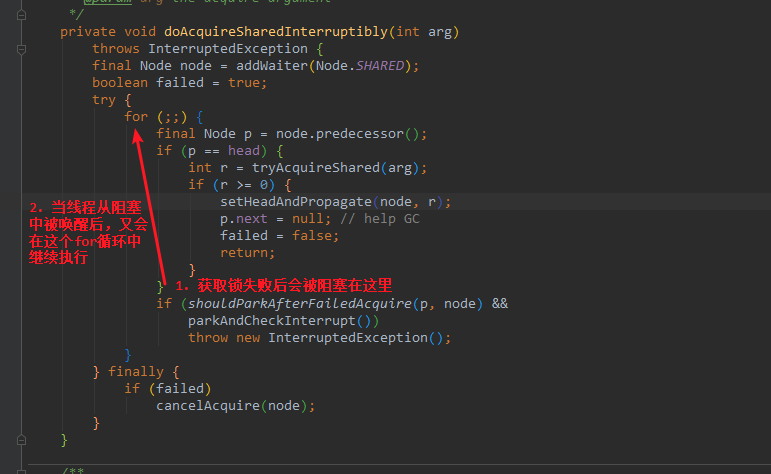
时刻3: 线程t4调用releaseShared(),读到此时waitStatue为0(和时刻1中的head是同一个head),不满足条件,因此不唤醒后继节点

时刻4: 线程t1获取锁成功,调用setHeadAndPropagate(),因为不满足propagate > 0(时刻2中propagate == 0),从而不会唤醒后继节点
如果没有PROPAGATE状态,上面的情况就会导致线程t2不会被唤醒。
那在引入了propagate之后这个变量又会是怎样的情况呢?
时刻1: 线程t3调用doReleaseShared,然后唤醒队列中结点(线程t1),此时head的状态从-1变成0
时刻2: 线程t1由于t3释放了信号量,被t3唤醒,然后通过nonfairTryAcquireShared()取得propagate值为0
时刻3: 线程t4调用releaseShared(),读到此时waitStatue为0(和时刻1中的head是同一个head),将节点状态设置为PROPAGATE(-3)
1 | else if (ws == 0 && |
时刻4: 线程t1获取锁成功,调用setHeadAndPropagate(),虽然不满足propagate > 0(时刻2中propagate == 0),但是waitStatus<0,所以会去唤醒后继节点
至此我们知道了PROPAGATE的作用,就是为了避免线程无法会唤醒的窘境。,因为共享锁会有很多线程获取到锁或者释放锁,所以有些方法是并发执行的,就会产生很多中间状态,而PROPAGATE就是为了让这些中间状态不影响程序的正常运行。
doReleaseShared-小方法大智慧
无论是释放锁还是申请到锁都会调用doReleaseShared()方法,这个方法看似简单,其实里面的逻辑还是很精妙的。
1 | private void doReleaseShared() { |
这其中有一个判断条件
1 | ws == 0 &&!compareAndSetWaitStatus(h, 0, Node.PROPAGATE) |
这个if条件成立也巧妙
- 首先队列中现在至少有两个节点,简化分析,我们认为它只有两个节点,head –> node
- 执行到else if,说明跳过了前面的if条件,说明头结点是刚成为头结点的,它的waitStatus为0,尾节点是在这之后加入的,发生这种情况是shouldParkAfterFailedAcquire()中还没来得及将前一个节点的ws值修改为SIGNAL
- CAS失败说明此时头结点的ws不为0了,也就表明shouldParkAfterFailedAcquire()已经将前驱节点的waitStatus值修改为了SIGNAL了
而整个循环的退出条件是在h==head的时候,这个是为什么呢?
由于我们的head节点是一个虚拟节点(也可以叫做哨兵节点),假设我们的同步队列中节点顺序如下:
head --> A --> B --> C
现在假设A拿到了共享锁,那么它将成为新的dummy node(虚拟节点),
head(A) --> B --> C
此时A线程会调用doReleaseShared方法唤醒后继节点B,它很快就获取到了锁,并成为了新的头节点
head(B) --> C
此时B线程也会调用该方法,并唤醒其后继节点C,但是在B线程调用的时候,线程A可能还没有运行结束,也正在执行这个方法,
当它执行到h==head的时候发现head改变了,所以for循环就不会退出,又会继续执行for循环,唤醒后继节点。
至此我们共享锁分析完毕,其实只要弄明白了AQS的逻辑,依赖于AQS实现的Semaphore就很简单了。在看共享锁源码过程中尤其需要注意的是方法是会被多个线程并发执行的,所以其中很多判断是多线程竞争情况下才会出现的。同时需要注意的是对于共享锁并不能保证线程安全,仍然需要程序员自己保证对共享资源的操作是安全的。