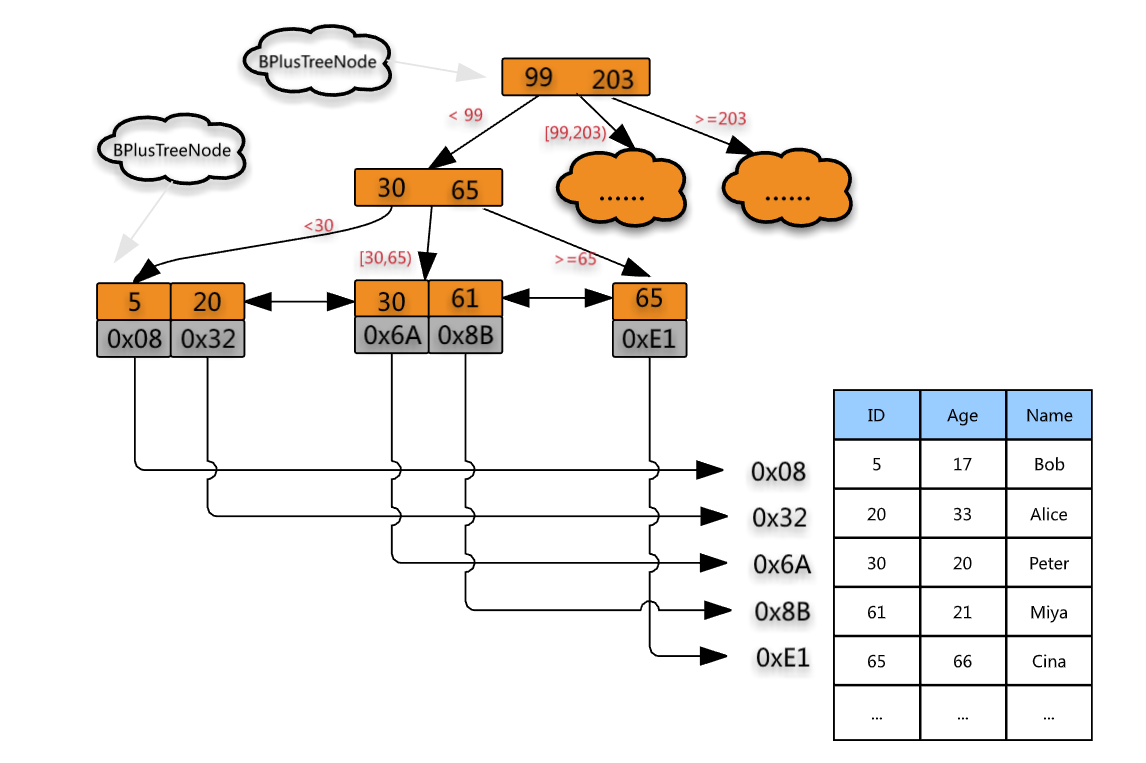
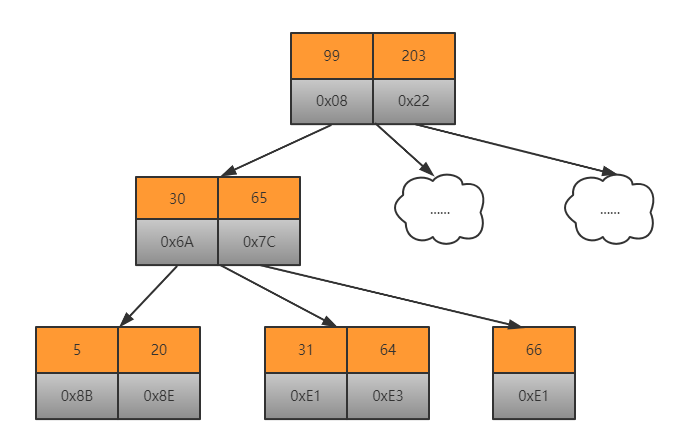
B +树的每个节点可以包含更多节点,其原因有两个,其一是降低树的高度(索引不会全部存储在内存中,内存中可能撑不住,所以一般都是将索引树存储在磁盘中,只是将根节点放到内存中,这样对每个节点的访问,实际上就是访问磁盘,树的高度就等于每次查询数据时磁盘 IO 操作的次数),另一种是将数据范围更改为多个间隔。间隔越大,数据检索越快(可以想象跳表)
每个节点不在是存储一个key,而是存储多个key
叶节点来存储数据,而其他节点用于索引
叶子节点通过两个指针相互链接,顺序查询性能更高。
这样设计还有以下优点:
B +树的非叶子节点仅存储键,占用很小的空间,因此节点的每一层可以索引的数据范围要宽得多。换句话说,可以为每个IO操作搜索更多数据
我们初高中的时候,都学过排列,它的概念是这么说的:从 n 个不同的元素中取出m(1≤m≤n)个不同的元素,按照一定的顺序排成一列,这个过程就叫排列。当 m=n 这种特殊情况出现的时候,就是全排列(All Permutation)。如果选择出的这 m 个元素可以有重复的,这样的排列就是为重复排列(否则就是不重复排列。
JAXB(Java Architecture for XML Binding简称JAXB)允许Java开发人员将Java类映射为XML表示方式。JAXB提供两种主要特性:将一个Java对象序列化为XML,以及反向操作,将XML解析成Java对象。换句话说,JAXB允许以XML格式存储和读取数据,而不需要程序的类结构实现特定的读取XML和保存XML的代码。