commons-logging
commons-logging是apache提供的一个通用的日志接口,是为了避免和具体的日志方案直接耦合的一种实现。通过commons-logging用户可以自己选择log4j或者jdk自带的logging作为具体实现。
使用commons-logging的代码如下
1 | import org.apache.commons.logging.Log; |
commons-logging是apache提供的一个通用的日志接口,是为了避免和具体的日志方案直接耦合的一种实现。通过commons-logging用户可以自己选择log4j或者jdk自带的logging作为具体实现。
使用commons-logging的代码如下
1 | import org.apache.commons.logging.Log; |
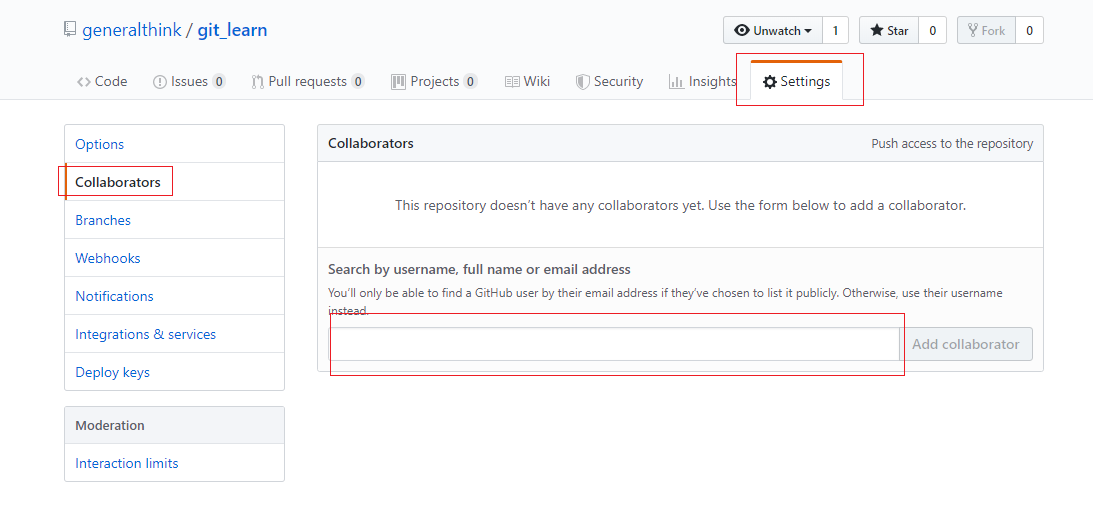
老大喊我记录下API的操作日志,免得前端甩锅,主要记录新增,修改,删除等操作。我想了下就决定用AOP来实现这个功能。
由于使用的是SpringBoot,所以首先应该在依赖中引入AOP包。
1 | <dependency> |
一般引入了AOP之后,一般不用做其他特殊配置,也不用加上@EnableAspectJAutoProxy注解。但是它仍有两个属性需要我们注意
上一篇文章分析了HashMap的原理,有网友留言想看LinkedHashMap分析,今天它来了。
LinkedHashMap是HashMap的子类,在原有HashMap数据结构的基础上,它还维护着一个双向链表链接所有entry,这个链表定义了迭代顺序,通常是数据插入的顺序。
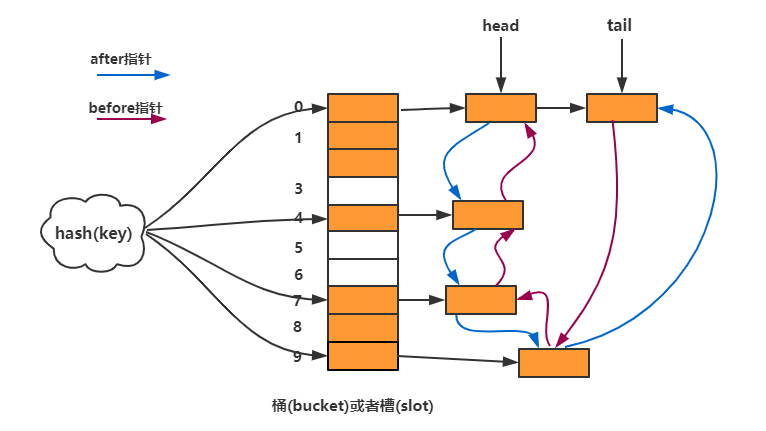
上一篇文章中提到了ThreadLocalMap是使用开放地址法来解决冲突问题的,而我们今天的主角HashMap是采用了链表法来处理冲突的,什么是链表法呢?
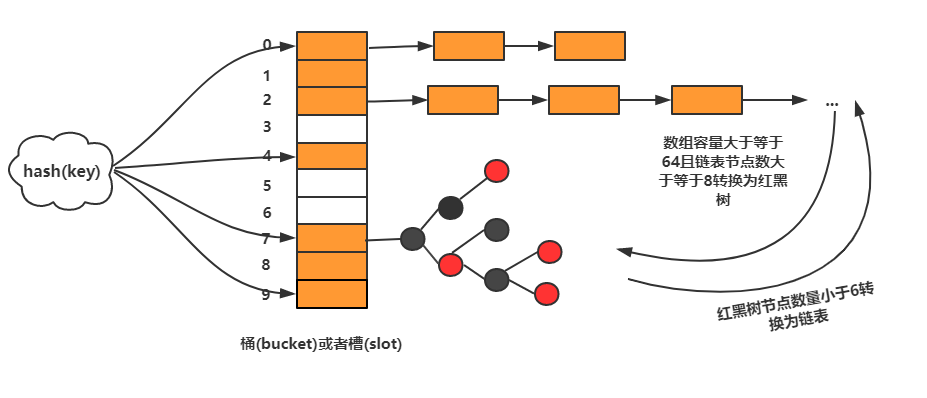
在散列表中,每个 “ 桶(bucket)” 或者 “ 槽(slot)” 会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
jdk8和jdk7不一样,jdk7中没有红黑树,数组中只挂载链表。而jdk8中在桶容量大于等于64且链表节点数大于等于8的时候转换为红黑树。当红黑树节点数量小于6时又会转换为链表。
散列表(hash table)我们平时也叫它哈希表或者Hash表,它用的是数组支持按照下标随机访问数据的特性,所以散列表其实就是数组的一种扩展,由数组演化而来。可以说,没有数组就没有散列表。
比如我们有100件商品,编号没有规律的4位数字,现在我们想要通过编号快速获取商品信息,如何做呢?我们可以将这100件商品信息放到数组里,通过 商品编号%100这样的方式得到一个值,值为1的商品放到数组中下标为1的位置,值为2的商品,我们放到数组中下标为2的位置。以此类推,编号为K的选手放到数组中下标为K的位置。因为商品编号通过散列函数(编号%100)跟数据下标一一对应,所以但我们需要查询编号为x的商品信息的时候,我们使用同样的方式,将编号转换为数组下标,就可以从对应的数组下标的位置取出数据。
这就是散列的典型思想。
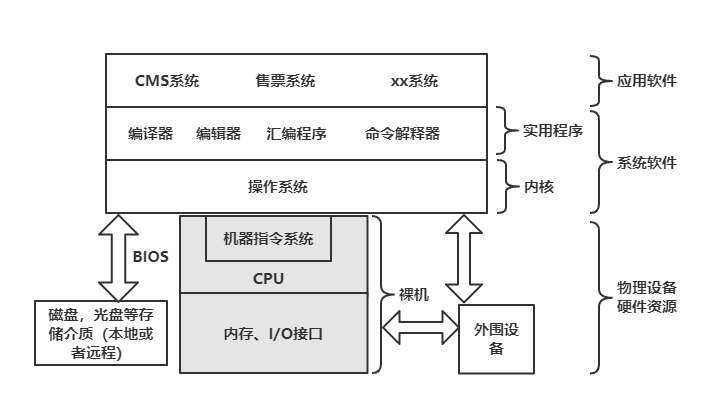
计算机系统是由“硬件”和“软件”两大部分组成,计算机硬件包括一个或多个处理器(CPU)、内存、键盘、显示器、磁盘、I/O接口以及其他一些外围设备比如打印机,绘图仪等等。
总之,计算机硬件部分是一个由多种电子和机械设备组成的硬件系统。
为了让人方便正确使用这些设备,就需要编写若干程序来管理这些设备,正是这些程序组成了计算机的软件系统。软件也可以分为两大类:系统软件和应用软件。人们首先直接在硬件上加载一层程序,用它来管理整个计算机硬件设备以及一些软件信息资源,同时还为用户提供开发应用程序的环境,这就是操作系统软件和实用软件。应用软件是在操作系统支持下,为实现用户要求而编制的各种应用程序。
MongoDB中存在一种索引,叫做TTL索引(time-to-live index,具有生命周期的索引),这种索引允许为每一个文档设置一个超时时间。一个文档达到预设置的老化程度后就会被删除。
数据到期对于某些类型的信息非常有用,例如机器生成的事件数据,日志和会话信息,这些信息只需要在数据库中保存有限的时间。
在createIndex中指定expireAfterSeconds选项就可以创建一个TTL索引:
1 | // 超时时间为24小时,默认是前台运行,可以通过background:true设置为后台模式 |
MongoDB有4个粒度级别的锁
MongoDB本身只提供Global,Database,Collection三个级别的锁,Document级别的锁是由存储引擎提供的(Wired Tiger提供了Document级别的锁)
任何一种数据库都有各种各样的日志,MongoDB也不例外。MongoDB中有4种日志,分别是系统日志、Journal日志、oplog主从日志、慢查询日志等。这些日志记录着MongoDB数据库不同方面的踪迹。下面分别介绍这几种日志。