什么是索引
要理解索引,你需要在脑中有个画面,这里建议想象一本食谱,不是普通食谱,而是5000页的厚重食谱,包含各种场合、菜肴和季节的食谱。虽然这个食谱很全,但是它有个缺点就是它是乱序的,第一页可能是鱼香茄子,第3000页是红烧茄子。
这还不是很要紧,关键问题是这本食谱没有索引!
下面是你要问自己的第一个问题:如果没有索引如何在食谱中找到糖醋排骨?唯一的选择是一页一页翻过去,如果它在3892页,你得要翻多少页呀,最坏的情况是它在最后一页,你就得把整本书都翻一遍。
解决办法就是构建一个索引。
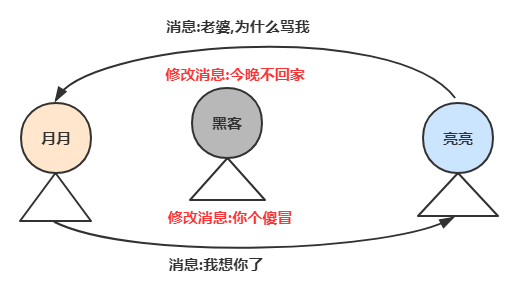
consumer提供三种不同的分区策略,可以通过partition.assignment.strategy参数进行配置,默认使用的策略是org.apache.kafka.clients.consumer.RangeAssignor,还存在org.apache.kafka.clients.consumer.RoundRobinAssignor和org.apache.kafka.clients.consumer.StickyAssignor这两种,它们的关系图如下所示。
上一篇讲了consumer如何加入consumer group的,现在加入组成功之后,就要准备开始消费,但是我们需要知道consumer从offset为多少的位置开始消费。
consumer中关于如何消费有2种策略:
1. 手动指定
调用consumer.seek(TopicPartition, offset),然后开始poll
2. 自动指定
poll之前给集群发送请求,让集群告知客户端,当前该TopicPartition的offset是多少,这也是我们此次分析的重点.
consumer比producer要复杂许多,producer没有组的概念,也不需要关注offset,而consumer不一样,它有组织(consumer group),有纪律(offset)。这些对consumer的要求就会很高,这篇文章就先从consumer如何加入consumer group说起。
GroupCoordinator是运行在服务器上的一个服务,负责consumer以及offset的管理。消费者客户端的ConsumerCoordinator负责与GroupCoordinator进行通信。Broker在启动的时候,都会启动一个GroupCoordinator服务。
对于 consumer group 而言,是根据其 group.id 进行 hash 并通过一定的计算得到其具对应的 partition 值(计算方式如下),该 partition leader 所在 Broker 即为该 Group 所对应的 GroupCoordinator,GroupCoordinator 会存储与该 group 相关的所有的 Meta 信息。
__consumer_offsets 这个topic 是 Kafka 内部使用的一个 topic,专门用来存储 group 消费的情况,默认情况下有50个 partition,每个 partition 默认三个副本。
partition计算方式:abs(GroupId.hashCode()) % NumPartitions(其中,NumPartitions 是 __consumer_offsets 的 partition 数,默认是50个)。
比如,现在通过计算abs(GroupId.hashCode()) % NumPartitions的值为35,那么就找第35个partition的leader在哪个broker(假设在192.168.1.12),那么GroupCoordinator节点就在这个broker。
同时这个消费者所提交的消费位移信息也会发送给这个partition leader所对应的broker节点,因此这个节点不仅是GroupCoordinator而且还保存分区分配方案和组内消费者位移。
我们已经知道了如何发送数据到Kafka,既然有数据发送,那么肯定就有数据消费,消费者也是Kafka整个体系中不可缺少的一环
1 | public class KafkaConsumerDemo { |
前几篇文章分析了Kafka的发送流程以及NIO的使用方式,但是还是留下了不少坑,这里就对剩下的问题做一个总结。
Kafka中Selector读取从远端回来的数据的时候会先把收到的数据缓存起来
1 | private void attemptRead(SelectionKey key, KafkaChannel channel) throws IOException { |
在NetworkClient中,往下传的是一个完整的ClientRequest,进到Selector,暂存到channel中的,也是一个完整的Send对象(1个数据包)。但这个Send对象,交由底层的channel.write(Bytebuffer b)的时候,并不一定一次可以完全发送,可能要调用多次write,才能把一个Send对象完全发出去。这是因为write是非阻塞的,不是等到完全发出去,才会返回。
1 | Send send = channel.write(); |
这里如果返回send==null就表示没有发送完毕,需要等到下一次Selector.poll再次进行发送。所以当下次发送的时候如果Channel里面的Send只发送了部分,那么此次这个node就不会处于ready状态,就不会从RecordAccumulator取出要往这个node发的数据,等到Send对象发送完毕之后,这个node才会处于ready状态,就又可以取出数据进行处理了。
同样,在接收的时候,channel.read(Bytebuffer b),一个response也可能要read多次,才能完全接收。所以就有了上面的while循环代码。
从上面知道,底层数据的通信,是在每一个channel上面,2个源源不断的byte流,一个send流,一个receive流。
send的时候,还好说,发送之前知道一个完整的消息的大小。
但是当我们接收消息response的时候,这个信息可能是不完整的(剩余的数据要晚些才能获得),也可能包含不止一条消息。那么我们是怎么判断消息发送完毕的呢?
对于消息的读取我们必须考虑消息结尾是如何表示的,标识消息结尾通常有以下几种方式:
很明显第一种和第三种方式不是很合适,因此Kafka采用了第二种方式来确定要发送消息的大小。在消息头部放入了4个字节来确定消息的大小。
1 | //接收消息,前4个字节表示消息的大小 |
上一篇文章虽然讲了epoll的原理,但是我相信还是有人觉得很迷惘,这里换个简单的说法再说下OP_WRITE事件。
OP_WRITE事件的就绪条件并不是发生在调用channel的write方法之后,也不是发生在调用channel.register(selector,SelectionKey.OP_WRITE)后,而是在当底层缓冲区有空闲空间的情况下。因为写缓冲区在绝大部分时候都是有空闲空间的,所以如果你注册了写事件,这会使得写事件一直处于写就绪,选择处理现场就会一直占用着CPU资源。所以,只有当你确实有数据要写时再注册写操作,并在写完以后马上取消注册。
这个参数指定了生产者在收到服务器响应之前可以发送多少个消息,找Kafka Producer中对应有一个类InFlightRequests,表示在天上飞的请求,也就是请求发出去了response还没有回来的请求数,这个参数也是判断节点是否ready的关键因素。只有ready的节点数据才能从Accumulator中取出来进行发送。
在谈NIO之前,简单回顾下内核态和用户态
内核空间是Linux内核运行的空间,而用户空间是用户程序的运行空间,为了保证内核安全,它们之间是隔离的,即使用户的程序崩溃了,内核也不受影响。
内核空间可以执行任意命令,调用系统的一切资源,用户空间只能执行简单运算,不能直接调用系统资源(I/O,进程资源,内存分配,外设,计时器,网络通信等),必须通过系统接口(又称 system call),才能向内核发出指令。
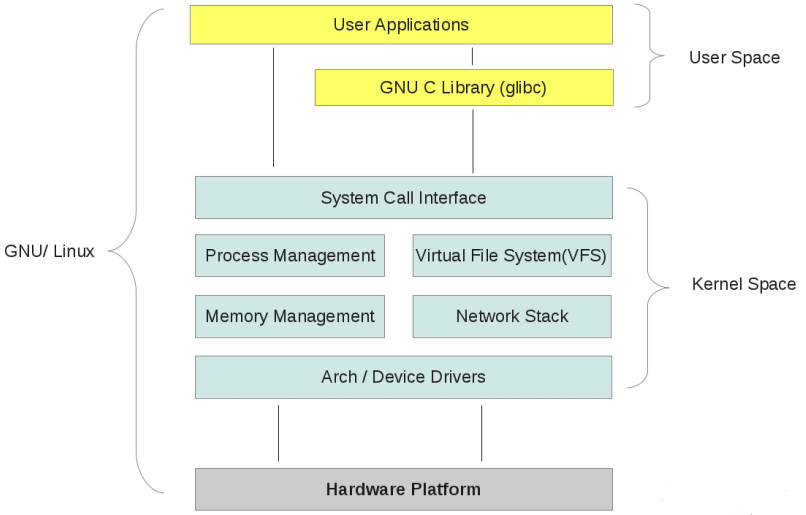
上一篇讲了Kafka Producer发送消息的主体流程,这一篇我们关注下Kafka的网络层是如何实现的。
对于发送消息而言,Producer是客户端,Broker是服务器端。
Kafka使用了JavaNIO向服务器发送消息,所以在这之前需要了解java nio的基本知识。这次网络层源码分析从metadata request切入。
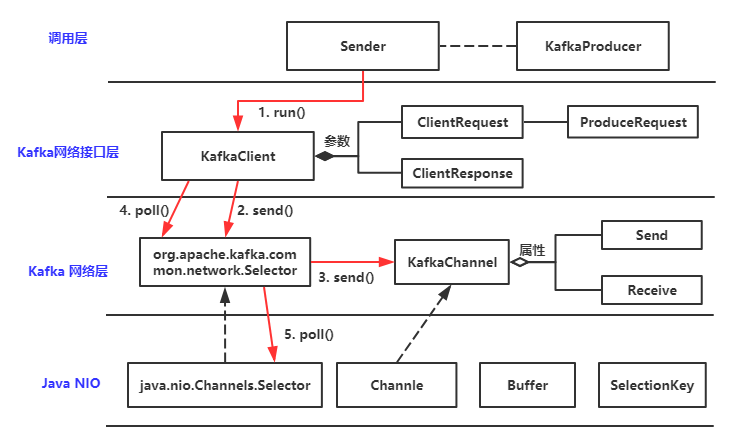
故事还要从月月给她老公亮亮发了一条消息说起。