实参和形参
1 | public int sum(int x,int y) { |
上面的代码中sum()方法中的x,y就是形参,而调用方法sum(2,3)中的2与3就是实参。形参是在方法定义阶段,而实参实在方法调用阶段。
之前看了许多介绍Java8 Stream的文章,但是初次接触真的是难以理解(我悟性比较低),没办法只能”死记硬背”,但是昨天我打王者荣耀(那一局我赢了,牛魔全场MVP)的时候,突然迸发了灵感,感觉之前没有理解透彻的一下子就理解透彻了。所以决定用简单的方式来回忆下我认为的java8 Stream.
lambda表达式是Stream API的基石,所以想要学会Stream API的使用,必须先要理解lambda表达式,这里对lambda做一个简单回顾。
我们常常会看到这样的代码
1 | Arrays.sort(new Integer[]{1, 8, 7, 4}, new Comparator<Integer>() { |
talk is easy,show me the code,先来看一段创建producer的代码
1 | public class KafkaProducerDemo { |
大家好,我是kafka,可能很多人都听说过我,知道我是2011年出生在LinkedIn的,从那会儿到现在我的功能越发强大了。作为一个优秀而又完整的平台,你可以在我上面冗余地存储巨大的数据量,我有一个具有高吞吐量(数百万/秒)的消息总线,你可以在这上面对经过我的数据进行实时流处理。
如果你认为我就只有上面的这些特点的话,那么你真的是太肤浅了。
上面虽然说的很好,但是并未触及到我的核心,这里我给你几个关键字:分布式,水平可扩展,容错,提交日志。
上面这些抽象的词语,我会一一解释它们的含义,并告诉你们我是如何工作的。
内心独白: 本来我是想要以第一人称来写这篇文章的,但是我发现我只能写出上面的了,再多的我就憋不出来了,于是我决定不要为难自己,还是用用第三人称写吧(写作的功底仍然需要锻炼)
前面的文章讲的命令都是操作本地仓库的,我相信可以应付大部分的开发状况,提交代码到本地仓库已经不是问题了,那么这次我们就来看看如何和远程仓库进行对接。
当我们进行开发的时候,开发流程是这样的:首先将远程仓库(中央仓库)的代码clone到本地,在本地进行开发,开发完成之后将代码提交到远程仓库。
远程仓库并不复杂,实际上它们只是你的仓库在另外一台计算机上的拷贝,我们可以通过网络和这台计算机通信–也就是增加或是获取提交记录。我们先通过命令将远端仓库clone到本地
1 | git clone https://github.com/generalthink/git_learn.git |
执行命令之后git仓库就从远端clone到本地了,此时本地和远端的代码一致。执行了这个命令之后我们本地有什么变化呢?
先查看我们现在存在哪些分支
1 | $ git branch -a |
上篇文章讲了merge和rebase,我们已经可以在commit object构成的图(当然我更愿意把它看成一棵树)上面进行分支的合并了,在图上我们可以新增节点(git commit),合并节点(merge或者rebase),这篇我们就来讲解下移动和删除节点。
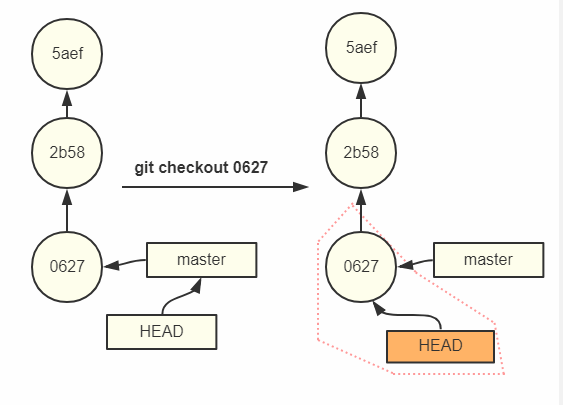
在讲移动和删除之前,我们先来认识下HEAD的分离。
我们都知道,HEAD是指向当前分支的,而分离的HEAD就是让其指向了某个具体的提交记录而不是分支名。
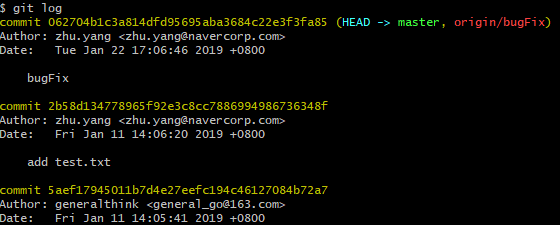
现在我本地的提交记录是这样的
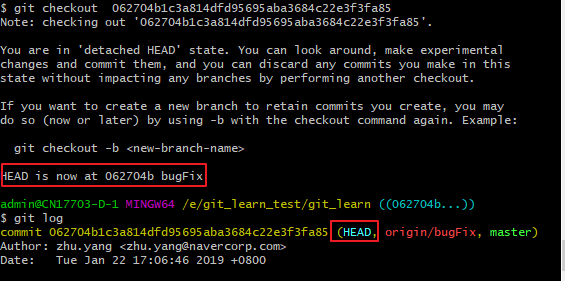
当我们执行git checkout 062704b1c3a814dfd95695aba3684c22e3f3fa85之后HEAD就处于分离状态。
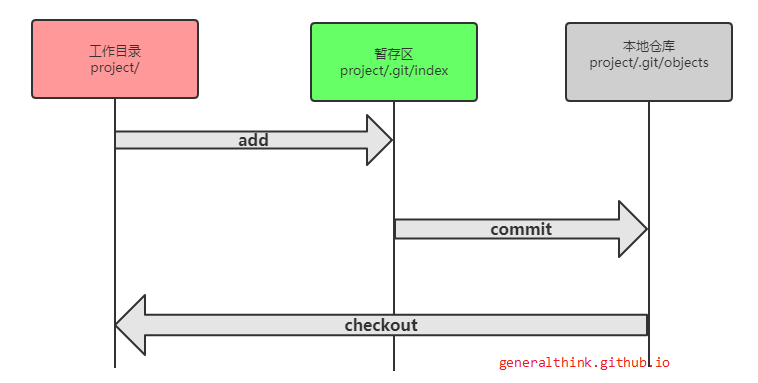
经过前面理论的学习,相信对git的模型已经有了一个比较深入的认识,在讲解常用开发命令之前,先看下git整体操作流程
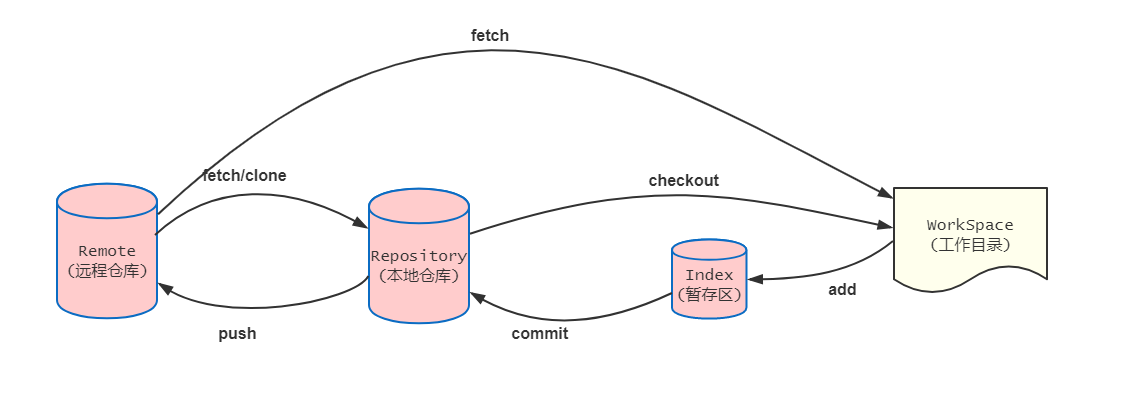
我们按照一个正常的开发流程来学习,我们现在要开始开发了,首先我们需要把远程仓库同步到本地
1 | git clone https://github.com/generalthink/git_learn.git |
运行完上面的命令,在我们的当前工作目录就会有一个git_learn的文件夹,其中存在.git目录(git维护仓库的基本)以及和远程仓库一样的文件,现在我们的代码环境就和远程仓库一致了,我们就可以开始我们的开发流程了。
在开发软件的时候,可能很多人会同时为同一个软件开发功能或者修复bug,但是如果都在主分支来进行开发,引起冲突的概率将会大大增加,而且也不利于维护,如果你同时修改多个bug该怎么办?所幸,git的分支功能很好的帮助我们解决了这个问题,它可以帮助我们同时进行多个功能的开发和版本管理.
请在阅读这篇文章之前,务必先阅读深入浅出git——数据模型,这样才能更好的帮助你理解git中的分支.想知道为什么git中新建一个分支那么快,代价那么小吗?接下来我们就来揭开分支神秘的面纱.
自2005年诞生以来,git已经在开源世界中大受欢迎,我们中的许多人也在我们的工作岗位上使用它。 它是一个很棒的VCS工具,具有很多优点,但易于学习并不是其中之一。 对于git如果只会死记硬背命令那么要不了多久你就会忘记,然后一而再而三的背诵,无疑让人很受打击,在我看来,熟悉使用git甚至开始喜欢它的唯一方法是了解它如何在内部工作。
git命令只是对数据存储的抽象,如果不了解git的工作原理,无论我们在笔记中记忆或存储了多少git命令或技巧我们仍然会对git的使用感到困惑.而git则是通过抽象的命令来暴露它的数据结构的使用方法.
所以这边文章我们更多的要关注git的内部关系-数据模型,当然这篇文章不会涉及到git的源码.