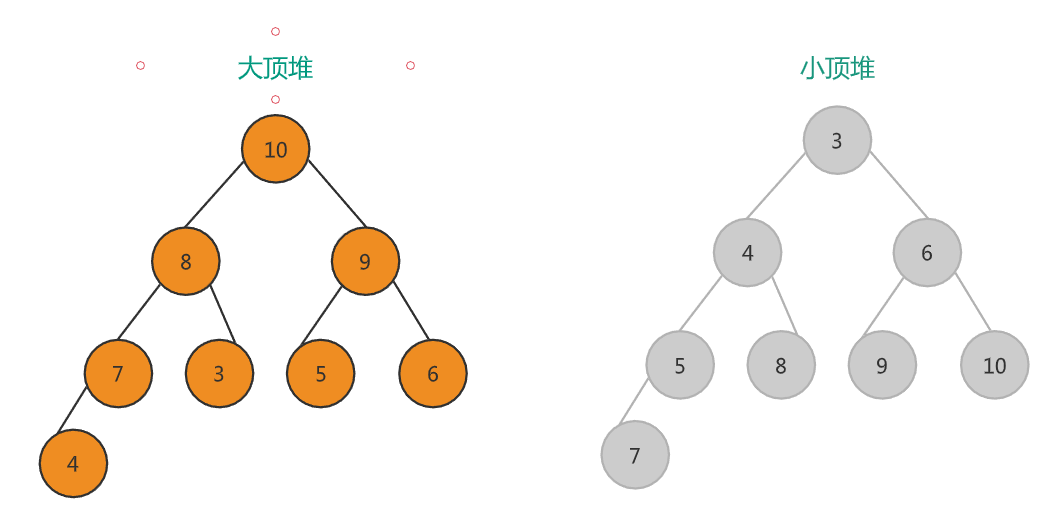
单体架构
下图简单展示了单体架构的工作流程
单体架构是把所有的模块和功能集中到一起,部署到一台服务器中,这种一把梭的方式,赢了还好,输了就下海干活。如果请求过大,一台机器撑不住,也只能通过添加机器的方式来进行横向扩展。
不要在git仓库中存储任何敏感信息,并且要不惜一切代价这样做,即使仓库是私有的,也不应该将其视为存储敏感信息的安全场所,首先让我们了解为什么它存储敏感信息不安全。
git上如果你将你的仓库声明为public的,那么任何一个人都可以访问你仓库的内容,不仅如此,还可以游览仓库中的所有代码,甚至可以运行它。如果你将你的API秘钥存储在仓库中,那么任何人都可以拿到。
即使是存储在私有仓库,也会面临风险。当你与第三方程序集成的时候,你可能正在向第三方应用打开私有仓库。这些应用程序时可以访问你的私有仓库并阅读其中包含的信息。攻击者就有可能伪装成这些第三方应用来获取你的机密数据(API key,数据库密码等等)。
代理服务器充当你和Internet之间的网关,就像一个中间人。它实际上是一个中间服务器,可以将用户与它们游览的网站区分开。
如果你使用了代理服务器,那么网络流量会通过代理服务器流向你请求的地址。然后该请求通过同一台代理服务器返回,然后代理服务器将从网站接收到的数据转发给你。
当然如果仅仅是这样,也没什么必要使用代理服务器,我们直接访问网站岂不更美?
现在代理服务器的功能远不只是转发Web请求,而这一切都是为了保证数据安全和网络性能。代理服务器充当防火墙和Web筛选器,提供共享的网络连接,并缓存数据以加快常见请求的速度。
而且还可以保护用户和内部网络以免收到外部Internet的不良影响。
Dockerfile是Docker用来构建镜像的文本文件,包括自定义的指令和格式。可以通过docker build命令从Dockerfile中构建镜像。用户可以通过统一的语法命令来根据需求进行配置,通过这份统一的配置文件,在不同的文件上进行分发,需要使用时就可以根据配置文件进行自动化构建,这解决了开发人员构建镜像的复杂过程。
我相信大家在项目中或多或少的都使用过线程,而线程是宝贵的资源,不能频繁的创建,应当给其他任务进行复用,所以就有了我们的线程池。
你知道我们如何创建线程池吗?
这我当然知道了,JDK主要提供了三种创建线程池的方法
线程池如何使用
1 | ExecutorService threadPool = Executors.newFixedThreadPool(5); |
你给我讲讲线程池的原理呢?
上面说的创建线程池的方法实际上都是通过创建ThreadPoolExecutor这个类来实现的,所以我们直接看这个类的实现原理即可。
首先来看看它的构造方法
1 | public ThreadPoolExecutor(int corePoolSize, |
先说下它这几个核心参数的含义
当然只是知道这几个参数也没有什么太大的作用,我们还是要着眼全局来看ThreadPoolExecutor类。
首先来认识下线程池中定义的状态,它们一直贯穿在整个主体
1 | // ctl存储了两个值,一个是线程池的状态,另一个是活动线程数(workerCount) |
从上面的成员变量的定义我们可以知道,线程池最多允许5亿个(2^29-1)个线程活动,那么为什么不是2^31-1呢?因为设计者觉得这个值已经够大了,如果将来觉得这是一个瓶颈的话,会把这个换成Long类型。
同时线程池这里也存在了五个状态,它们解决着线程池的生命周期。
状态流转图如下: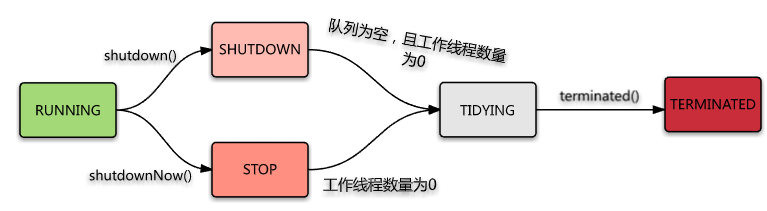
我们知道当我们执行一个task的时候,调用的是execute方法
1 | public void execute(Runnable command) { |
而在addWorker方法中还存在有一些必要的判断逻辑,比如当前线程池是否是非running状态,队列是否为空等条件,当然最主要的逻辑还是判断当前工作线程数量是否大于maximumPoolSize以及启动工作线程执行任务。
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
所以,总结下线程池的工作流程 如下:
如果你觉得上面不好记,我给你讲个火锅店的故事你就更加明白了。
以前有个火锅店,叫做朱帅帅火锅,老板是个刚辞掉程序员工作出来创业的帅小伙子,火锅店不大,只能摆上10张桌子(corePoolSize),如果吃火锅的来得早就可以去店里面坐(店里有空调),来晚了,店里面坐满了,后面来的人就要排队了(workQueue)。
排队的人数越来越多,朱帅帅一看不是办法,就给外面摆了几张临时桌子(非核心工作线程),让客人在外面吃。如果店里面有人吃完了或者外面临时桌子吃完了就让排队的人去吃。后面时间晚了,没有排队的人了,老板就让人撤了外面的临时桌子,毕竟摆在外面也不太好,而且还怕城管来。如果生意特别好,又来了特别多的人,已经超出火锅店的服务能力了,就只能喊他们去别家了。
上面的故事,你要品,细细的品,最后你会发现,代码来源于生活。
上面一直说到工作线程,工作线程到底是个什么鬼?其实工作线程指的就是我们的Worker类,它是ThreadPoolExecutor中的私有类
1 | private final class Worker |
可以看到Woker不仅继承了AbstractQueuedSynchronizer(实现独占锁功能),还实现了Runnable接口。
实际上线程池中的每一个线程被封装成一个Worker对象,ThreadPool维护的其实就是一组Worker对象
Worker用自己作为task构造一个线程,同时把外层任务赋值给自己的task成员变量,相当于对task做了一个包装。
addWorker()方法中执行了worker.thread.start(),实际上执行的就是Worker的runWorker方法。
1 | final void runWorker(Worker w) { |
** 上面的代码中尤其需要注意的是getTask()中的第3点,它的目的是控制线程池有效的工作线程数量。
从之前的分析我们可以知道,如果当前线程池的工作线程数量超过了corePoolSize且小于maximumPoolSize,并且workQueue已满,则可以增加工作线程,但这时如果超时没有获取到任务,也就是timedOut为true的情况,说明workQueue已经为空了,也就说明了线程池中不需要那么多线程来执行任务了,可以把多于corePoolSize数量的线程销毁掉,保持线程数量在corePoolSize即可。**
你刚才说到拒绝策略,都有哪些拒绝策略呀?
主要有下面4种拒绝策略
如果这四种策略都不满足需求,可以自己实现自己的拒绝策略。
你给我说说你开头说的通过Executors创建的线程池三者有何不同吗?
固定线程数量的线程池,corePoolSize等于maximumPoolSize,采用的阻塞队列是LinkedBlockingQueue,是一个无界队列,当任务量突然很大,线程池来不及处理,就会将任务一直添加到队列中,就有可能导致内存溢出。
创建单个线程的线程池,corePoolSize = maximumPoolSize = 1,也采用的LinkedBlockingQueue这个无界队列,当任务量很大,线程池来不及处理,就有可能会导致内存溢出。
创建可缓存的线程池,corePoolSize = 1,maximumPoolSize = Interger.MAX_VALUE;但是使用的是SynousQueue,这个队列比较特殊,内部没有结构来存储任何元素,所以如果任务数很大,而创建的那个线程(corePoolSize=1)迟迟没有处理完成任务,就会一直创建线程来处理,也有OOM的可能。
cacheThreadPool中的cache其实指的就是SynousQueue,当往这个队列插入数据的时候,如果没有任务来取,插入这个过程会被阻塞。
你既然说了都有可能OOM,那么应该如何创建线程池呢?
实际使用中不建议通过Executors来创建线程池,而是通过 new ThreadPoolExecutor的方式来创建,而队列也不建议使用无界队列,而要使用有界队列,比如ArrayBlockingQueue。而拒绝策略这个就看你自己需求了(系统提供的如果不满足,就自己写一个)
同时对于核心线程数的设置也不是越大越好,只能说根据你的需求来设置这个值,一般来讲可以根据下面两点来进行合理配置
当然啦,这个考虑是很多方面的,不仅仅和程序有关,还和硬件等资源有关,总之就是在测试的时候多多调试。
大家不要以为我上面说的是句废话,请你自信一点,把以为去掉。
Java8之前我们在写代码的时候,经常会遇到返回null的情况,如果这种情况不加以判断,你就会碰到NullPointerException(NPE)。而在Java8中,Optional类型是一种更好的表示缺少返回值的形式。
首先来看一段代码,这可能是以前大多数人的写法
1 | private void getIsoCode( User user){ |
现在很多项目都是web项目,前后端分离,唯一的交互就是通过restful接口,而当我们请求返回的时候,status code如何返回呢?
首先介绍下常用的http status code有哪些。
请求成功
文档创建成功,比如新增一个user成功
请求已被接受,但相应的操作可能尚未完成。这用于后台操作,例如数据库压缩等异步操作
请求参数有误(比如应该传一个Number类型的参数,你却传了一个字符串),请求无法被服务器理解,修改后可以重新提交这个请求
Kustomize是为了解决k8s yaml应用管理问题而生的一个工具,在1.14版本之后kubectl就集成了kustomize,而在这之前,我们则只能自己安装。
可以在github上下载对应操作系统的包进行安装(https://github.com/kubernetes-sigs/kustomize/releases)。
windows下它就是一个exe文件,我们把它放到某一个目录后,加入环境变量,即可在命令行中进行使用了。
1 | $ kustomize version |
1 | kubectl get namespace |
默认使用的是 ~/.kube/config这个配置文件,如果文件不再这个目录下可以通过 –kubeconfig configFilePath>指定
https://kubernetes.io/docs/tasks/access-application-cluster/configure-access-multiple-clusters/#set-the-kubeconfig-environment-variable